EAS Transcription
- Digital0 JPY

音声ファイルから文字を起こす、簡単(Easy)で(And)シンプル(Simple)なアプリです。 起こした文字はtxtファイルに保存されます。 ボーカル曲のファイルから、歌詞をテキストにする事も可能です。 対応ファイル形式はwav、mp3、m4a、flac、wma、aiffです。
公式サイト
https://otomona-works.sakura.ne.jp/
使い方
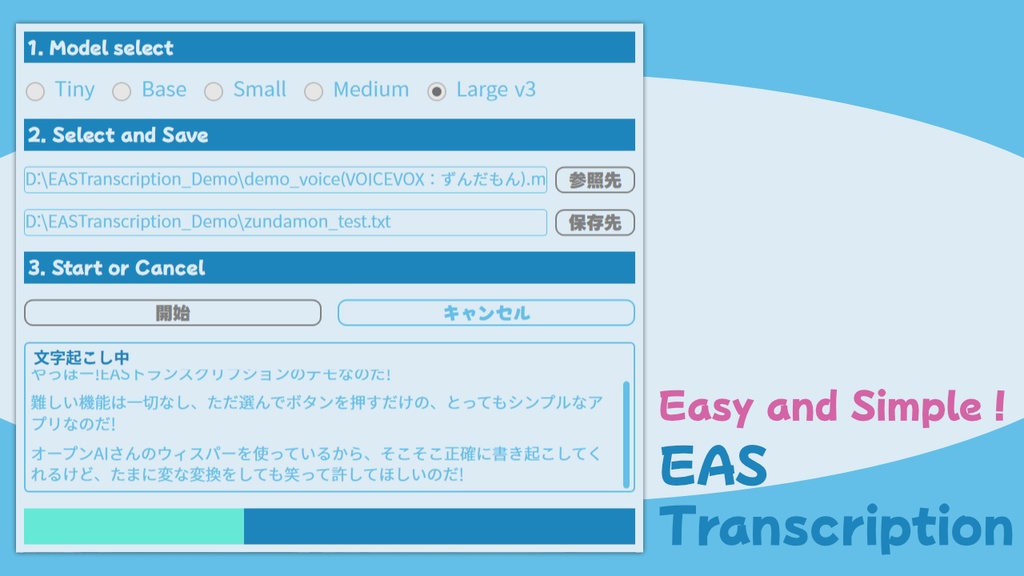
0. EAS_Transcription_v100.zipを解凍し、出来たフォルダの中にある「EASTranscription.exe」を実行して下さい。 .exeが見えない場合、windowsのフォルダオプション→表示→詳細設定欄にある「登録されている拡張子は表示しない」のチェックを外してください。 1. Model Select 音声認識のモデルを選択します。 選択したモデルのファイルが無い場合は、モデルのダウンロードが開始されます。 モデルのダウンロードは、該当のモデルを削除したりしない限り、再ダウンロードの必要はありません。 モデルのファイルが格納されるのは、実行ファイルのあるフォルダにある「WhisperModel」フォルダになります。 本アプリでは、OpenAIが開発した音声認識モデル「Whisper」を使用しています。 選択するモデルによって、文字起こしの「精度」と「処理速度」が大きく変わります。用途に合わせて最適なものを選択してください。 ・Tiny 動作確認・検証 圧倒的に高速ですが、誤字脱字や漢字変換ミスが多くなります。 ・Base ざっくりした確認 高速ですが、精度は控えめです。クリアな音声のメモ書き程度に。 ・Small 標準的な利用 精度と速度のバランスが最も良く、一般的な使用におすすめです。 ・Medium 丁寧な議事録作成 高い精度で書き起こせますが、処理には相応のマシンスペックが必要です。 ・Large v3 最高精度の追求 最も正確ですが、非常に重いです。高性能なGPU(VRAM 10GB以上推奨)環境向け。 2. Select and Save Modelが選択されていれば、以下の参照先ボタンと保存先ボタンが押せるようになります。 参照先ボタンを押し、文字起こしする音声ファイルを選択してください。 保存先ボタンを押し、起こした文字を保存するテキストファイルを設定してください。 3. Start or Cancel Modelが選択され、参照先と保存先が設定されていれば、開始ボタンを押す事ができます。 開始ボタンを押すと、画面下のスペースに処理状態が表示されます。 「文字起こし完了」のが出れば成功です。 キャンセルボタンは、開始ボタンを押した後に押せるようになり、文字起こし処理をキャンセルする事ができます。
動作環境
CPU: Windows 11対応CPU メモリ: 16GByte以上 GPU: NVIDIA製(CUDA対応モデル) ※1 対応OS: Windows 11 モニター解像度: 1360px * 768px 以上 ※1 NVIDIA製GPU(CUDA対応モデル)でなくても動作したりしますが、処理速度は低下します。