
Ai-Radar v3
- ダウンロード商品¥ 980
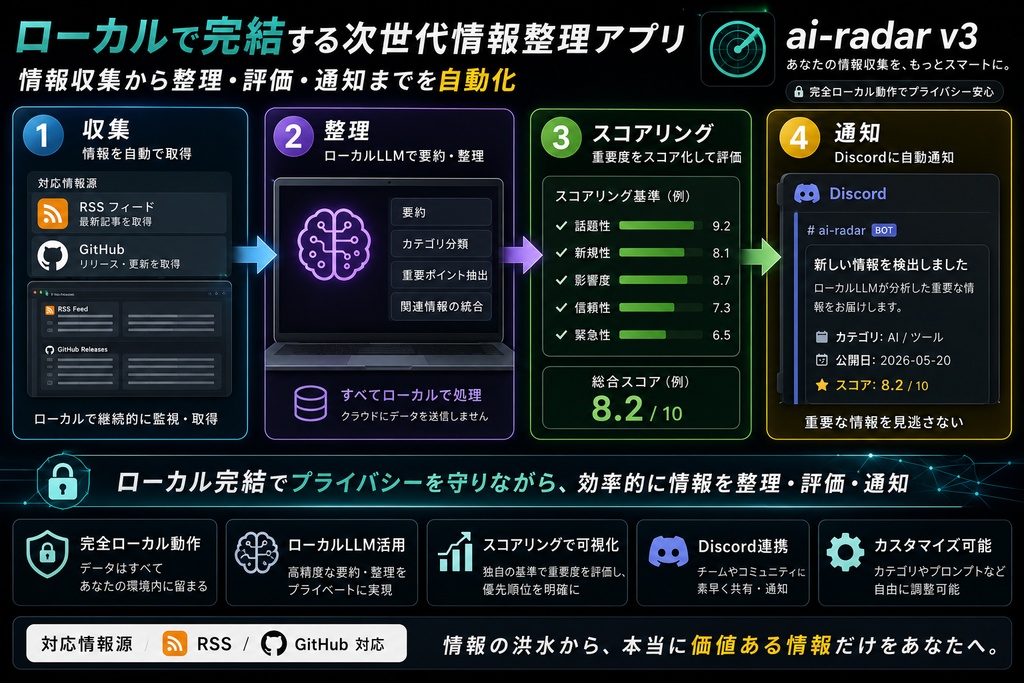

ai-radar v3 — ローカルAIで「読むべき情報だけ」をDiscordに届ける こんな悩みのための道具です AI・ローカルLLM・GPU まわりは情報の動きが速く、追いかけ続けるのがしんどい。 RSS を開き、GitHub の更新を見て、ニュースを巡回し……気づけば毎日それなりの時間を「情報を集めるだけ」に使っている。しかも、集めた大半は自分には関係のない内容です。 「全部に目を通すのは無理。でも見落としたくない」——この消耗を減らすために作りました。 何をするツールか ai-radar v3 は、登録した情報源(RSS / GitHub など)を定期的に集め、**重要度でふるいにかけてから**、本当に読むべきものだけを要約して Discord に通知します。 ポイントは「集める」ことではなく「**捨てる**」ことです。 既存ツールと何が違うか 更新検知ツール(changedetection.io など)は、差分が出たらその全文を毎回 LLM に投げて要約しようとします。これは重く、ノイズも多い。結局「通知は来るが、読む価値があるかは自分で判断」という状態になりがちです。 ai-radar v3 は順番が逆です。 要約する前に、重要度スコアで足切りする(filter before summarize)。 スコアの低いものは要約すらせず捨てる。だから LLM に渡す量が減り、軽く、手元に届くのは「読む価値があると判断されたものだけ」になります。この「フィルタしてから要約する」という設計が、このツールの核心です。 動作環境(完全ローカル) 本ツールは **クラウド API を使わず、ローカルLLM だけで完結**します。収集した情報を外部の API に送りません。 OS: Windows(Python 3.10+) LLM: Ollama または LM Studio(ローカル起動) クラウドAPI: 非対応(完全ローカル動作) 動作確認済み構成 Windows 11 / RTX 4070 Ti Super (16GB VRAM) / Ollama / qwen3 VRAM は 6〜8GB 以上を推奨。軽量モデル(qwen2.5:3b など)への切り替え手順も同梱しています。CPU でも動作しますが、実用的な速度は出ません。 セットアップ(README 同梱) 1. Ollama を入れて `ollama pull qwen3` 2. `setup.bat` をダブルクリック(環境構築は自動) 3. `run_web.bat` を起動して `http://localhost:5000` へ 4. 画面から自分の Discord webhook と監視対象を設定 5. 「Run Now」で動作確認、あとは Windows タスクスケジューラで定期実行 設定はすべてブラウザ上の管理画面で完結します。YAML を手で編集する必要はありません。 同梱物 本体一式(Flask 製の管理画面つき) README(セットアップ・定期実行・トラブルシュート) 設定済みの情報源テンプレート(そのまま使える初期設定) ご利用にあたって 個人利用ライセンス(再配布・再販はご遠慮ください) 現状有姿での提供です。動作を保証するものではありません ローカルLLM の知識が多少あるとスムーズです(README にトラブルシュートあり) その他 今回は AI・ローカルLLM 分野に特化したツールですが、「自分の分野でもこういう情報収集や作業を自動化したい」というご相談があれば歓迎します。お気軽にお声がけください。
動作環境(動作確認済み)
Windows 11 RTX 4070 Ti Super (16GB VRAM) Ollama qwen3