誰でもできるAI画像生成アート入門 2 (Stable Diffusion webUI編)
- 有料版Digital600 JPY
- お試し無料版Digital0 JPY






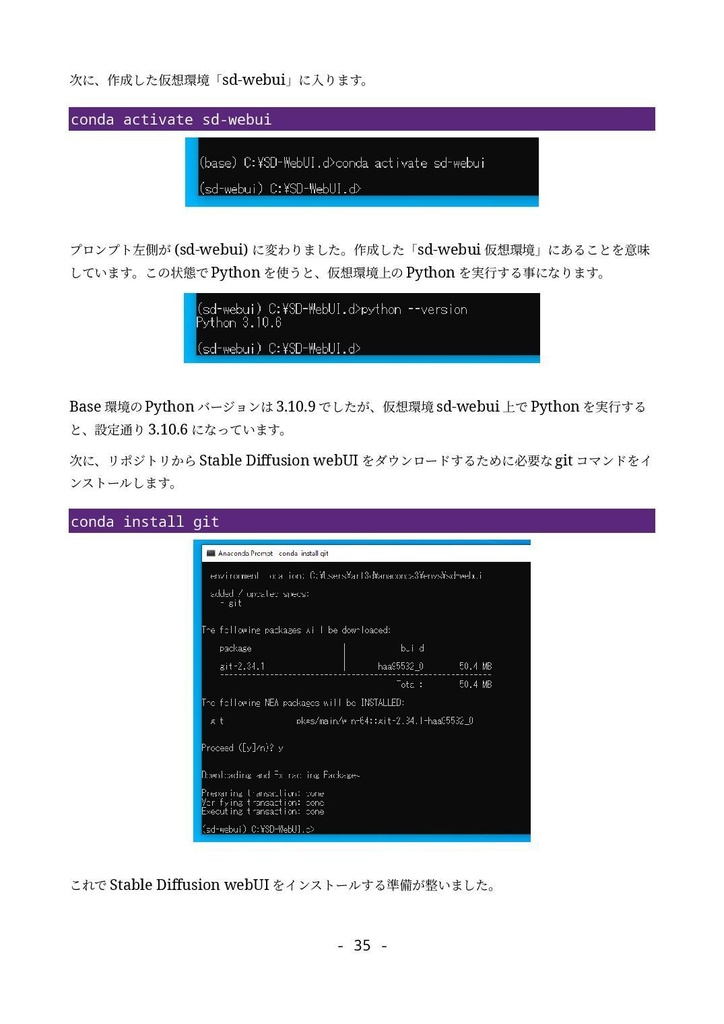


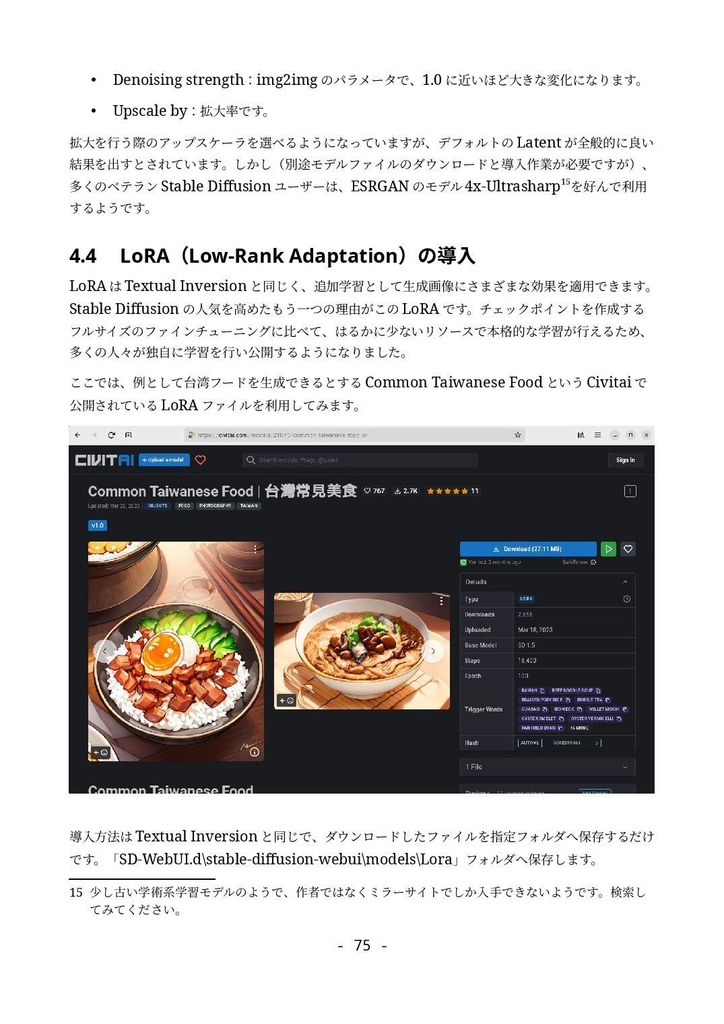


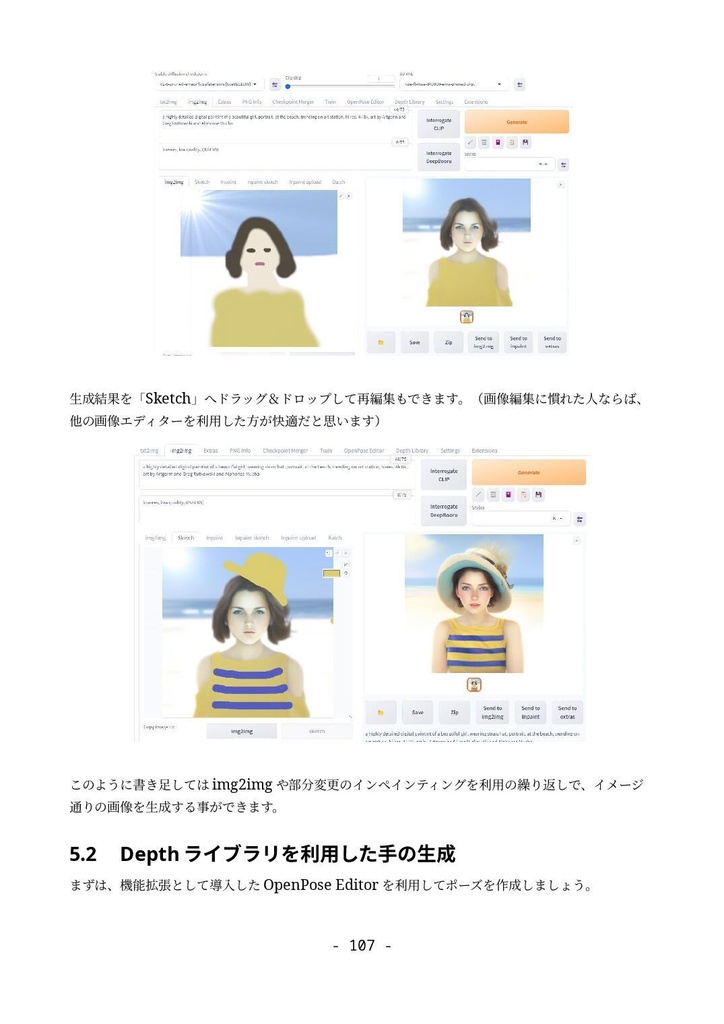
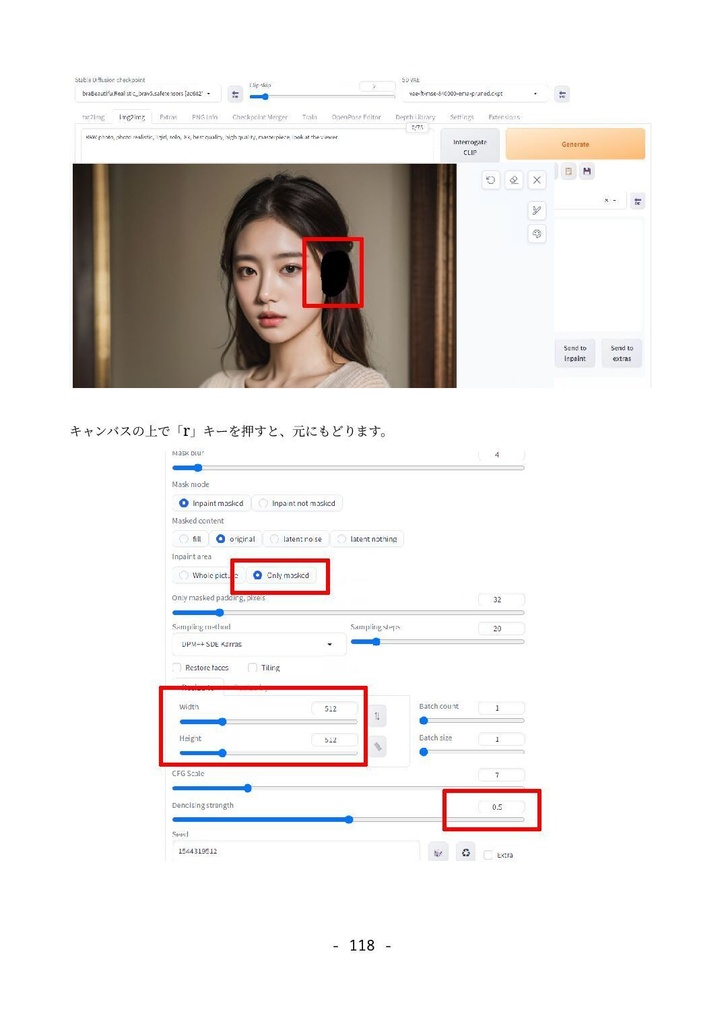

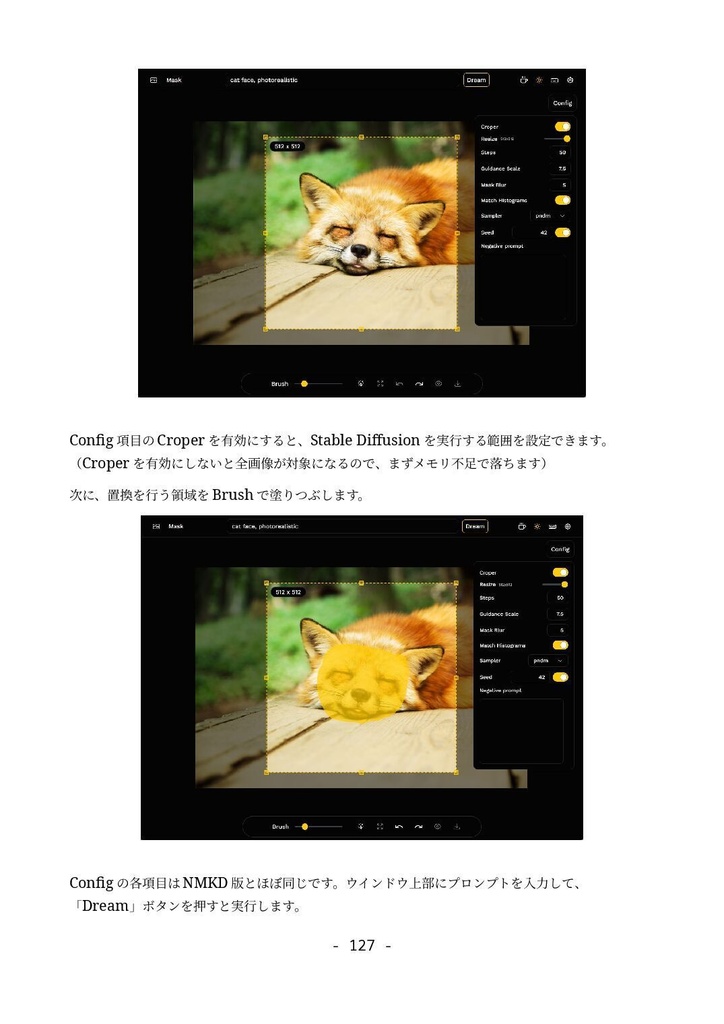
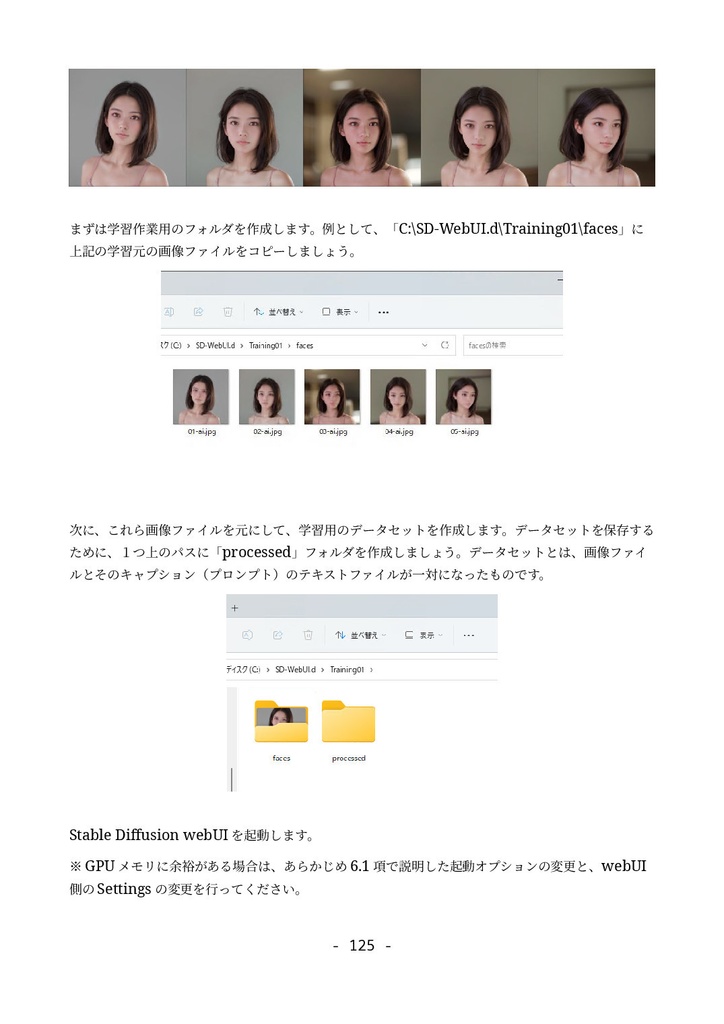
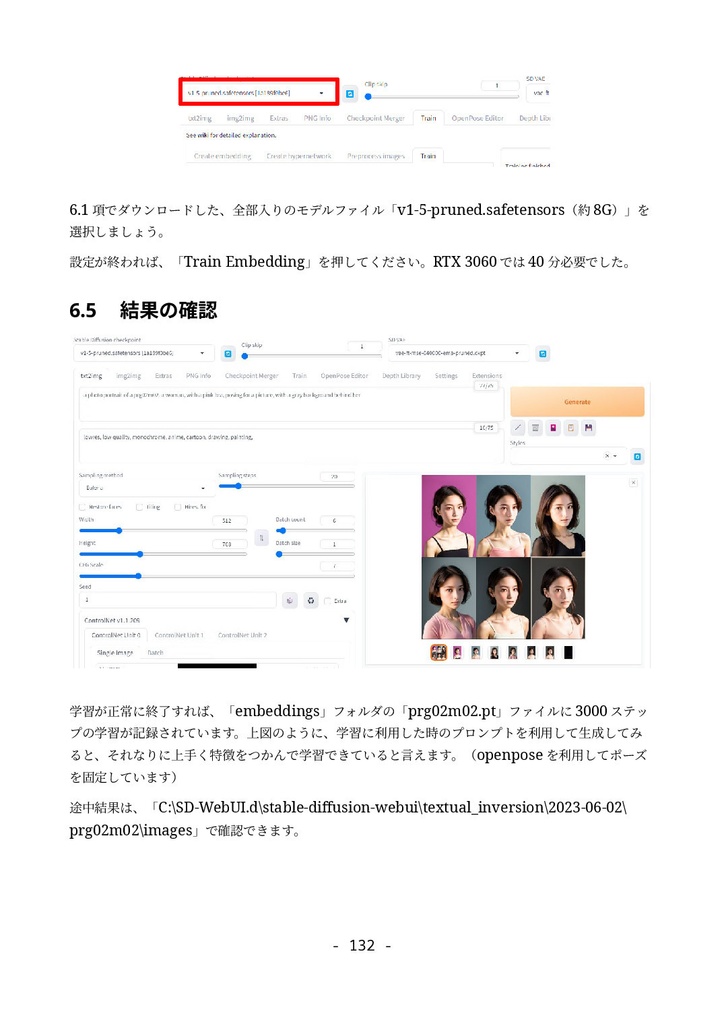

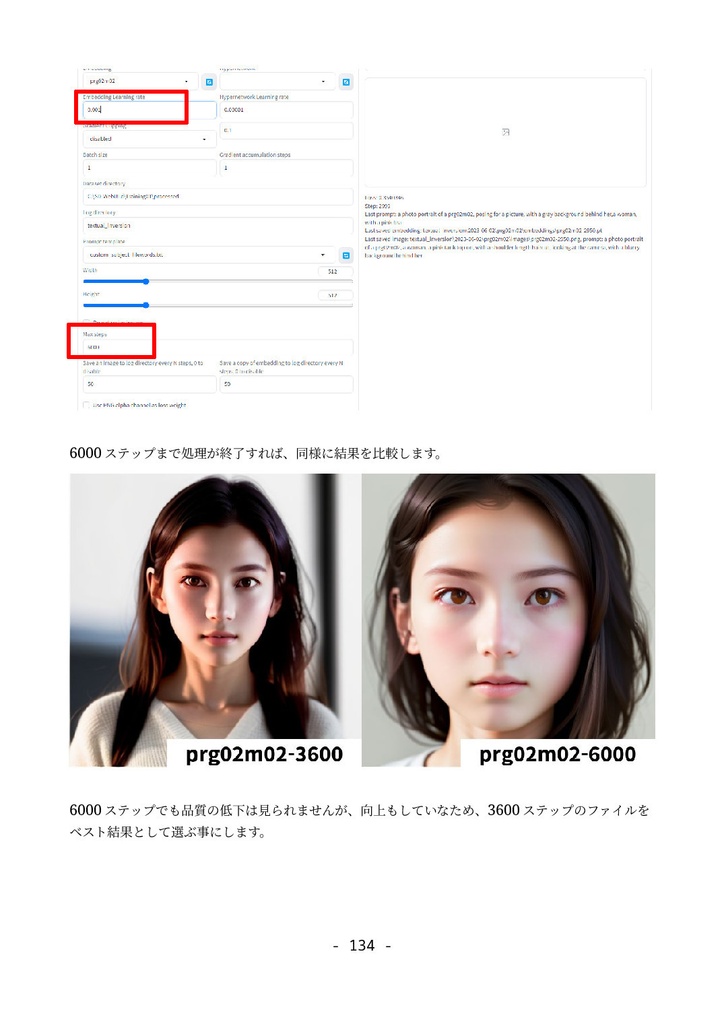










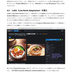








形式:PDF(著作権保護なし) 文字数:87,764文字 ページ数:182ページ 【注意】「(GTX1660tiではじめる)誰でもできるAI生成アート入門」をすでに購入いただいた方は、本ドキュメントも無料でダウンロードできます。https://catapp-art3d.booth.pm/items/4310567 よりダウンロード下さい。 はじめてAI画像生成(Stable Diffusion)を、ミドルレンジ・ゲーミングPC(RTX 3060)を使って、無料でかつローカル環境で試してみたい方に最適です。 誰も知らない最新の特殊な利用方法の紹介ではなく、導入やアップデート等の保守、はじめてAI画像生成を扱う人向けの一般的な用途や知識の説明を扱っています。 ローカルでAI画像を生成するソフトウェアでは最大の人気を誇る Stable Diffusion webUI を、はじめて利用する方を対象に、インストール方法から典型的な利用方法を丁寧にドキュメントにまとめました。 ネットで見かけるAI画像を、自分でも生成してみたい、ゲーミングPCでAIの限界を試してみたいなど、AI画像生成に興味のある方はぜひ一読くださいませ。 6章にて Textual Inversion による学習方法の解説を行っていますが、作業に利用するサンプル画像及び、学習によって得られた.pt学習ファイル(Embeddingファイル)も同梱しています。 ※前著「誰でもできるAI生成アート入門1」は、GTX1660tiでできる事+NMKD Stable Diffusion GUIを主に扱いましたが、「 誰でもできるAI生成アート入門2」は、 A1111版 Stable Diffusion webUIを扱ったものになります。 目次 1. はじめに 4 1.1 AI生成プログラムを実行するのに必要なパソコン 5 1.2 免責事項 6 2. AI画像生成の一連の流れ 7 2.1 Stable Diffusion webUIの起動 7 2.2 はじめの一歩 9 2.3 基本ワークフロー 13 2.3.1 シードでガチャ 13 2.3.2 パラメータの最適化 15 2.3.3 ポスト処理 17 2.3.4 さらに手を加える(Inpaint) 20 3. Stable Diffusion webUIのインストール 26 3.1 インストール作業 27 3.1.1 インストールの流れ 27 3.1.2 作業前の確認事項 27 3.1.3 Windows版Anacondaのインストール 28 3.1.4 Anaconda仮想環境の構築 33 3.1.5 Stable Diffusion webUIのインストール 36 3.1.6 画像生成の動作確認と起動設定 40 3.2 Stable Diffusion webUIの設定 41 3.2.1 省メモリ・高速化の起動オプション 41 3.2.2 webUI設定 43 Saving images/grids(画像・グリッド画像の保存) 44 Paths for saving(保存パス) 47 Saving to a directory(フォルダーへの保存) 47 Upscaling(アップスケーリング) 48 Face restoration(人の顔補正) 49 System(システム) 49 Stable Diffusion 49 Interrogate Options(プロンプト推測 インテリゲート・オプション) 51 Extra Networks(追加ネットワーク・追加学習モデル) 52 User interface(ユーザー・インターフェース) 53 Live previews(ライブ・プレビュー) 54 Sampler parameters(ノイズ・サンプラーのパラメーター) 55 Postprocessinig(ポスト処理) 55 Actions(その他動作) 56 3.3 メンテナンスとクリーン・インストールの方法 56 3.3.1 アップデート 57 3.3.2 クリーンインストール(レベル1) 57 3.3.3 クリーンインストール(レベル2) 58 3.3.4 クリーンインストール(レベル3) 59 3.4 日本語UIの導入 59 4. Stable Diffusion webUI 61 4.1 Prompt(呪文) 61 4.1.1 Promptの基本 62 4.1.2 ネット界隈で囁かれる法則 63 4.1.3 ネット情報の活用 65 4.2 野良モデルの導入 67 4.3 Textual Inversionの導入 72 4.4 LoRA(Low-Rank Adaptation)の導入 76 4.5 LyCORIS(LoCon/LoHa等LoRA亜種の統合)の導入 78 4.6 ControlNetの導入 82 4.6.1 ControlNetでできる事 82 4.6.2 ControlNetの導入手順 83 4.7 ControlNetの利用 87 4.7.1 基本ワークフロー 87 4.7.2 Multi-ControlNetの利用 93 4.7.3 その他ControlNetのモデル 95 4.8 VAE(Variational Auto Encoder)について 100 4.9 モデル(チェックポイント)のマージと変換 104 4.9.1 ckpt → safetensorsへの変換 104 4.9.2 モデルのマージ 105 4.9.3 インペインティング・モデルの作成 107 4.10 Stable Diffusion 2.1の導入 109 5. Stable Diffusion webUIの利用例 112 5.1 img2imgを利用したラフ画から画像生成 112 5.2 Depthライブラリを利用した手の生成 113 5.3 高品質グラビア画像の生成 118 5.4 生成画像の再利用 121 5.5 機能拡張Canvas Zoomと拡大inpaint 122 5.6 高解像度画像の生成 126 5.6.1 ControlNet(tile)を利用したアップスケーリング 126 5.6.2 Multidiffusionを利用したアップスケーリング 130 5.7 アウトペインティング 132 5.7.1 webUIのinpaint機能として行うoutpaint 133 5.7.2 img2img付属のスクリプトを利用したoutpaint 137 5.7.3 ControlNetを利用したoutpaint 138 5.7.4 拡張機能openOutpaintを利用したoutpaint 141 6. AI追加学習 148 6.1 前準備 148 6.2 Textual Inversionのしくみ 150 6.3 学習元ファイル(学習データセット)の準備 151 6.4 Embeddingファイルの作成と学習の実行 155 6.5 結果の確認 159 7. 付録 164 7.1 Lama Cleaner 164 7.1.1 インストール 165 7.1.2 SD1.5(Stable Diffusion 1.5)エンジンで画像置換 169 7.1.3 Lama Cleanerプラグイン 171 7.2 Conda仮想環境 176 7.3 Disty's Stable Diffusion Pickle Scanner GUI 178 7.4 HuggingFaceアクセストークンの取得方法 180 8. あとがき 182 2023/8/30 第1.3版