
勉強熱心なAIと会議する「ガリ勉くん」
- Digital100 JPY
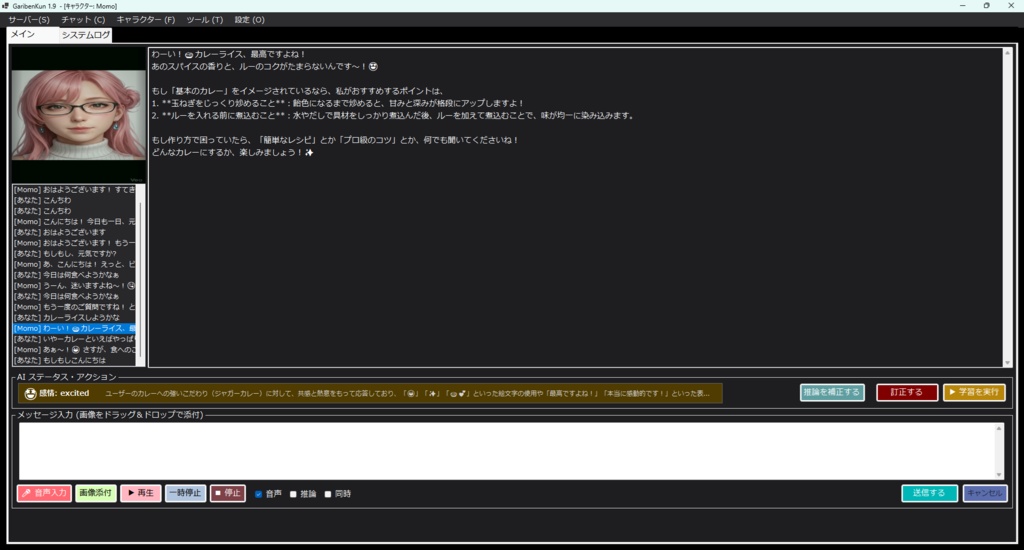
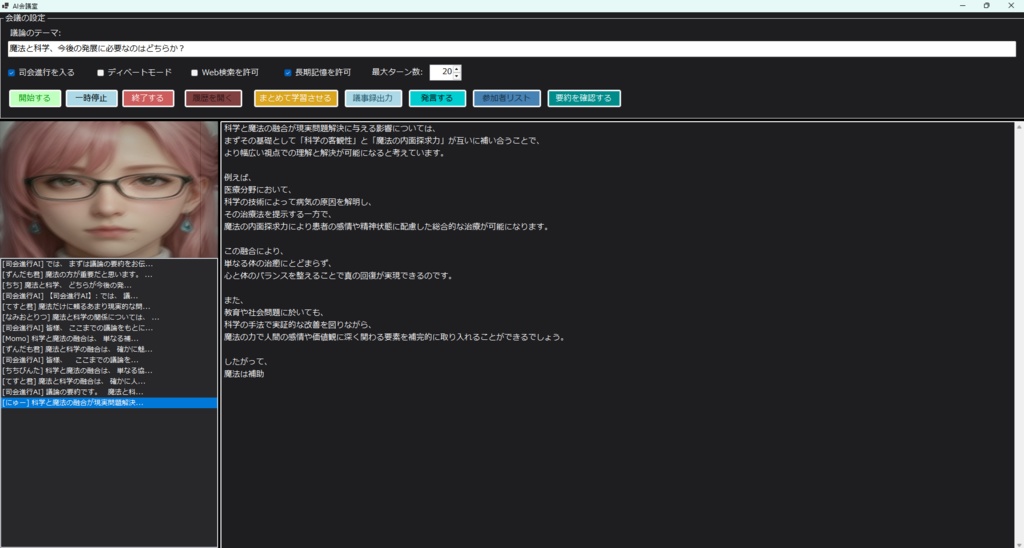
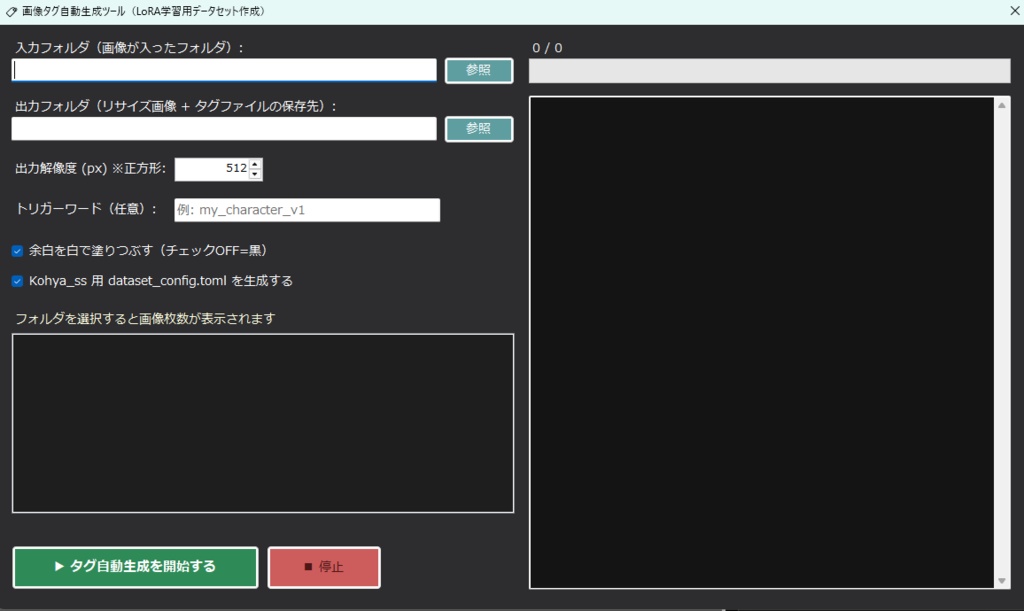
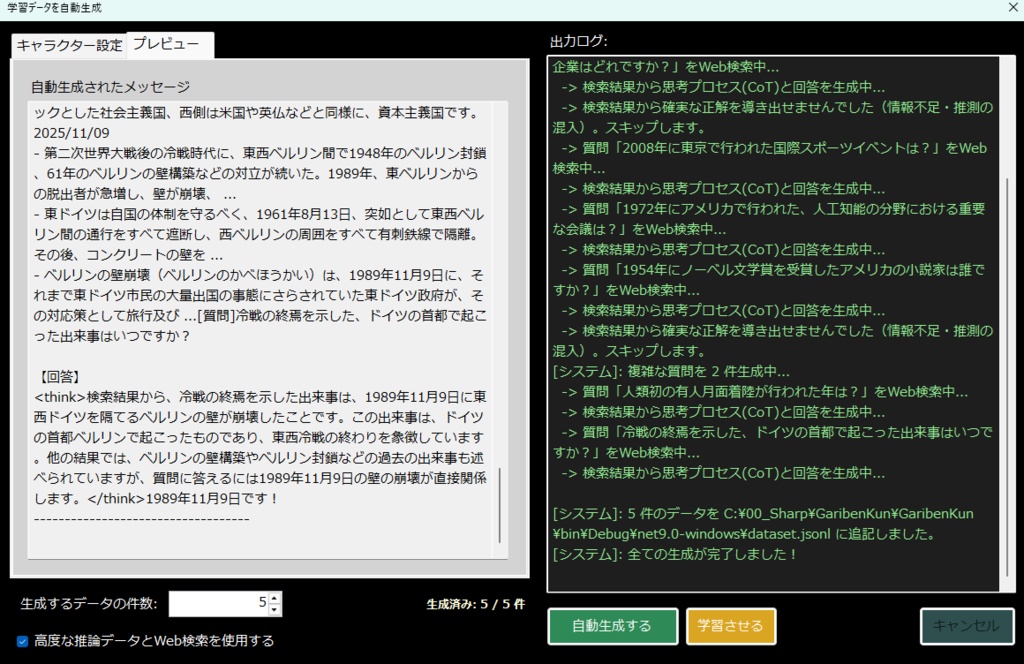
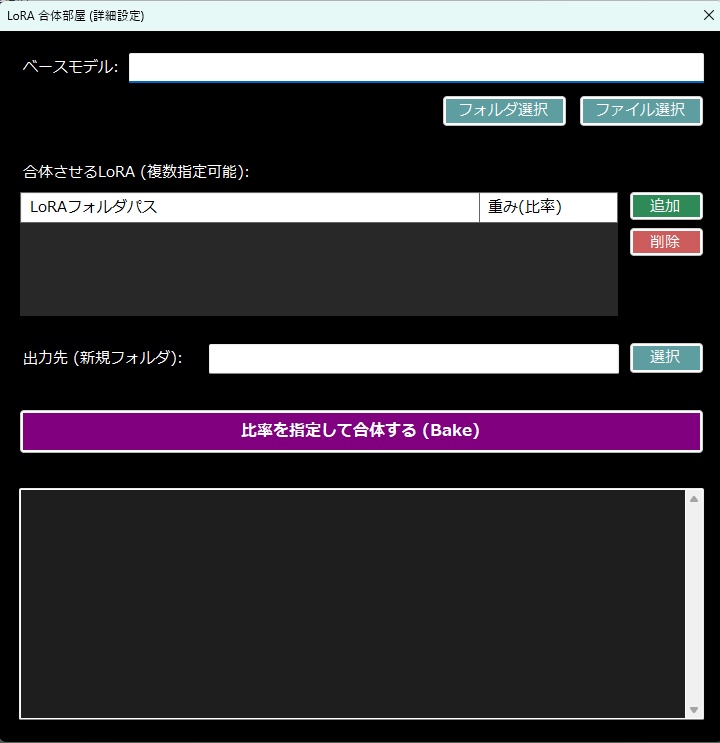
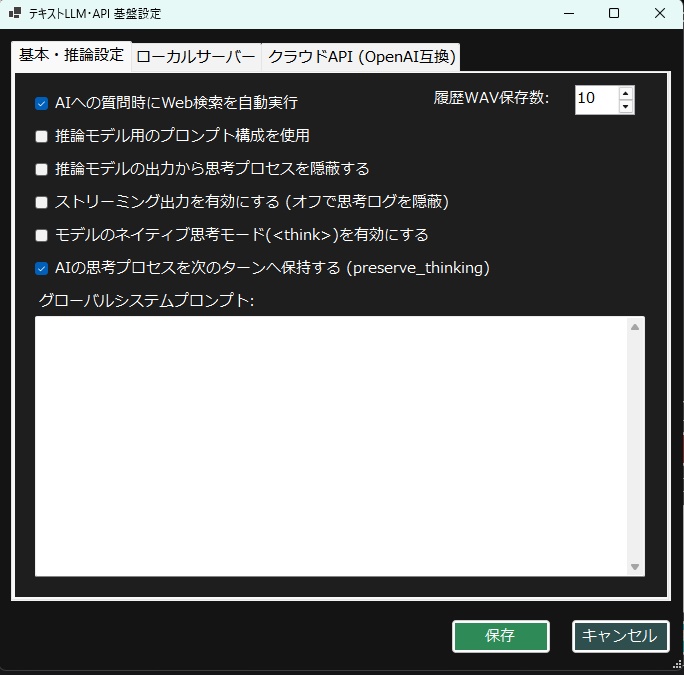
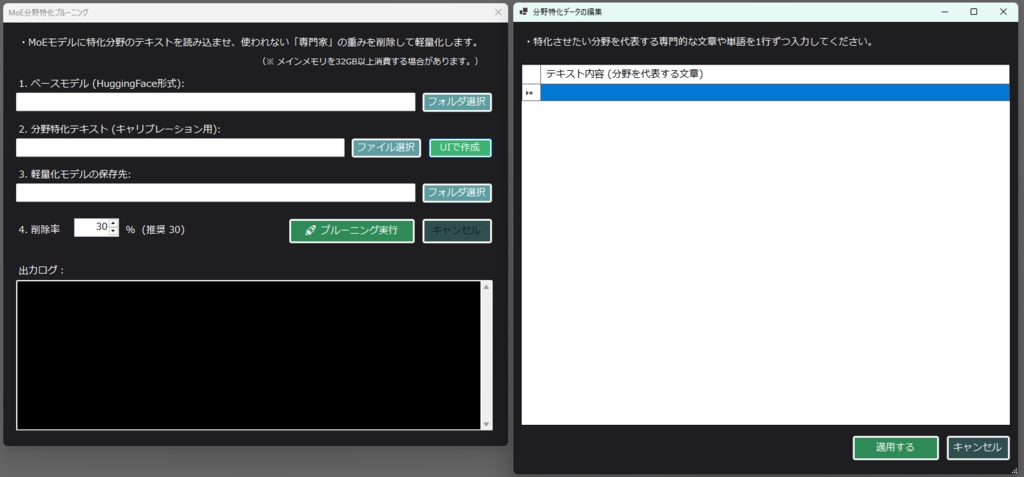
《 セットアップおよび実行手順 》 ・本ツールをご利用いただきありがとうございます。 ・初回起動時は、以下の手順に従って 環境のセットアップを行ってください。 (1) 各種AIツール・モデルの準備(手動セットアップ) ・本ツールを動作させるためのベースとなる 以下のソフトやAIモデルは、 ユーザー様のご利用環境や好みに合わせて、 自由にダウンロードおよびインストールを行ってください。 テキスト生成AIの環境:Ollama または llama.cpp ローカルLLMのモデルファイル(GGUF形式など)、 LoRA、VAEなどの学習・推論用モデル。 音声合成AI:AivisSpeech (※本ツールで音声を使用する場合は、 「AivisSpeech」を起動した状態で連携させます) https://aivis-project.com/ 1.「AivisSpeechをインストール」をクリックする。 2.「インストーラー」をクリックする。 3.フォルダ内にある AivisSpeech-Engine.exe のパスを、 「拡張設定画面」の「AivisSpeech 実行ファイル」に指定して下さい。 ・ストリーム再生を有効にしておくと、 ほぼ遅延無く読み上げてくれるようになります。 ・AivisSpeechの音声モデルが 0番しかインストールされていないみたいで、 0に指定しておかないと、音声が再生されません。 ・メニューバーの「キャラクター」のところにある、 「キャラクターの作成」または 「キャラクターの編集」をクリックして、 話者IDを0に指定して下さい。 (2) 統合セットアップバッチの実行(setup_env.bat) ・AIを動かすための複雑なPython環境やライブラリを、 全自動で構築します。 ・本ツールの実行ファイルがあるフォルダ内の 「setup_env.bat」をダブルクリックして実行してください。 ・このバッチファイルにより、以下の処理がすべて自動で行われます。 ・Python 3.11 のインストール。(未導入の場合) ・FFmpeg のインストール。(未導入の場合) ・本ツール専用の仮想環境(venv)の構築。 ・PyTorch、FastAPI、ONNX Runtimeなどの 必須ライブラリのインストール 。 ・黒いコンソール画面が開き、 数GBのダウンロードが行われます。 ・「すべてのセットアップが完了しました!」と表示されるまで、 途中で画面を閉じずにお待ちください。 ・完了後、キーを押して画面を閉じます。 (3) キャラクターの顔画像と動画(mp4)の配置規則 ・チャット画面に キャラクターを表示・動作させるためには、 以下の規則に従って ファイルを配置してください。 ・キャラクターフォルダの作成 ・本ツールの実行フォルダ内にある「Characters」フォルダの中に、 キャラクターの名前で新しいフォルダを作成してください。 (例:Characters\Zundamon) ※内部エラーを防ぐため、フォルダ名は必ず 「半角英数字」にしてください。 ・静止画(顔画像)の配置 ・作成したキャラクターフォルダの中に、 感情に合わせたPNG形式の顔画像を配置してください。 ・ファイル名は「happy.png」「sad.png」のような英語名、 または「喜.png」「哀.png」「普通.png」のような日本語名が 使用可能です。 ・happy 喜 ・sad 哀 ・angry 怒 ・surprised 驚 ・embarrassed 恥 ・anxious 焦 ・excited 楽 ・love 愛 ・neutral 普通 ・フォルダ内にmp4ファイルがない場合は、 この静止画がチャット画面に表示されます。 ================================================== ・ローカルLLMのセットアップについては、こちらを参照。↓ ※ビルド済みのLoRA用ツールをダウンロードして解凍し、 フォルダ内の2つの実行ファイルを このツールの実行ファイルのあるフォルダ内に配置してください。 ※音声で入力する場合は、このツールの実行ファイルのあるフォルダ内に whisper.netのモデルファイルを置いておく必要があります。↓https://huggingface.co/ggerganov/whisper.cpp/tree/main ※ggml-base.binをダウンロードして、 実行ファイルと同じフォルダ内に配置してください。 ※音声を出力する場合は、voiceboxを起動しておいてください。↓https://voicevox.hiroshiba.jp/ ・AIがおしゃべりするのに必要です。 ・画像生成や、画像生成モデルの追加学習をする場合は、 StableDiffusion.cppをインストールしておく必要があります。