AI論文年鑑 2026
Physical (worldwide shipping)

- 2026年版(紙版+電子版)Mailbin OKPhysical (via warehouse)3,200 JPY
Physical (ship to Japan)/ Digital Download
- 2026年版(紙版+電子版)Mailbin OKPhysical (via warehouse)3,200 JPY
- 2026年版(電子版)Digital2,000 JPY
- 2025年版(紙版+電子版)Out of StockMailbin OKPhysical (via warehouse)3,200 JPY
- 2025年版(電子版)Digital2,000 JPY






















































「使える技術」を探しやすく、「次に来る研究」も見つけやすく ── AI論文200本を厳選解説 おかげさまで 2025年版は 【第10回刺され!技術書アワード エポックメイキング部門 優秀賞 受賞】 しました! 紙版+電子版の電子版は「おまけファイル」からダウンロードできます
本書について
NeurIPS、CVPR、ICLRをはじめとする20以上の著名な国際学会から、商用利用可能なコードが公開されているAI論文200本を厳選し、各論文の要約と重要図表を収録した年鑑形式のサーベイ本です。昨年刊行した初版に続く2冊目となる本書では、論文の選定方法・収録範囲・解説の両面で大幅な改良を施しました。 本書の最大の特徴は、LLMを中心とした自動化パイプラインによって論文を選定・解説している点です。初版では「被引用数×GitHubスター数」という人気度ベースのスコアリングでしたが、本書ではLLMによるOriginality(独創性)とElegance(洗練性)の評価を主軸に据えました。引用数やスター数では埋もれがちな「ダークホース」的論文を正当に評価し、選定に反映しています。 また、初版ではCV系がクラスタの大半を占めていましたが、本書ではCV・NLP・音声などの分野ごとにクラスタリングを行い、各分野に最低クラスタ数を保証。収集対象も20以上のカンファレンスに拡充し、ICASSP・Interspeech(音声)、KDD(データマイニング)、NAACL・EMNLP(自然言語処理)などを新たにカバーしています。 さらに、各章の冒頭にサーベイ記事を新設しました。クラスタに属する全論文をLLMに入力し、研究動向・主要アプローチ・今後の展望をまとめています。各論文を読む前に全体像をつかむことで、個別の論文の位置づけが理解しやすくなります。
各論文の掲載情報
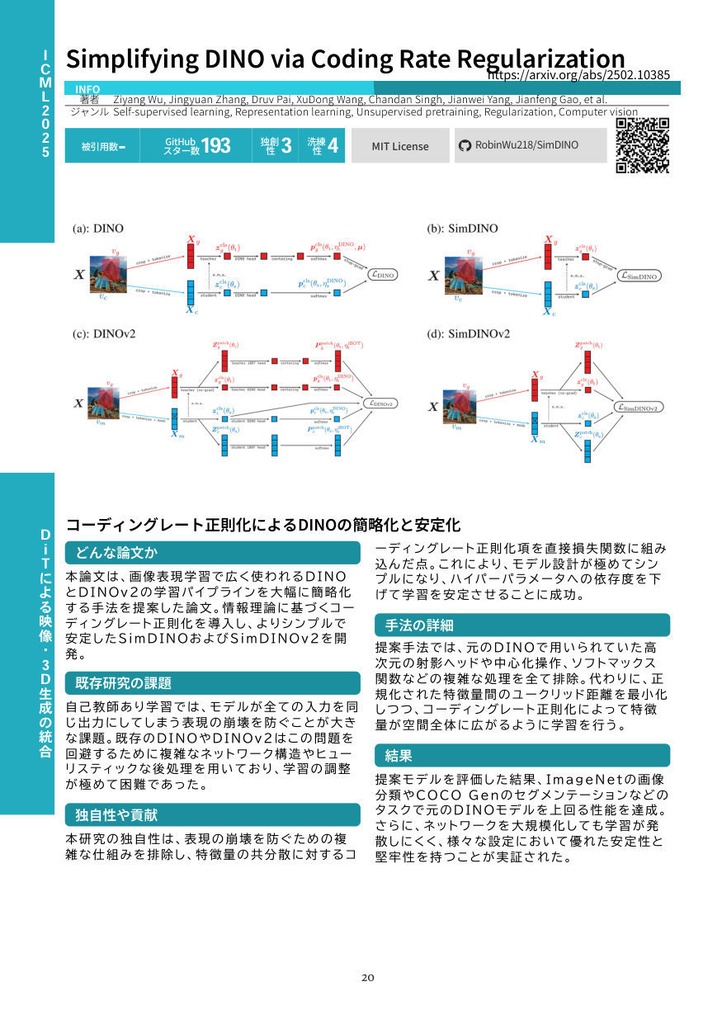
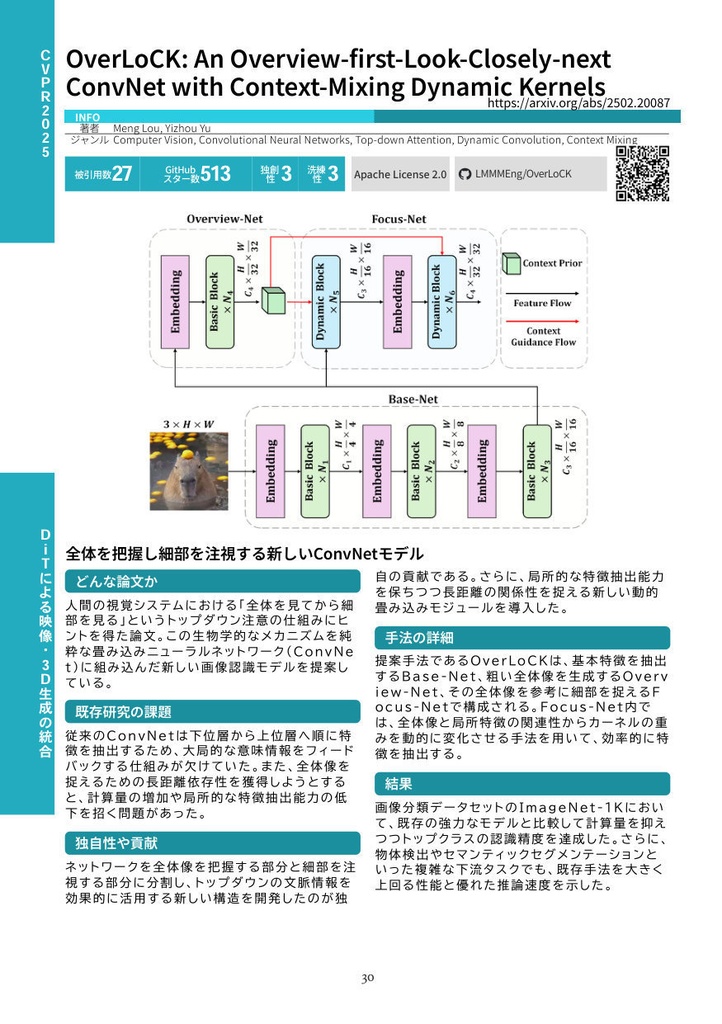
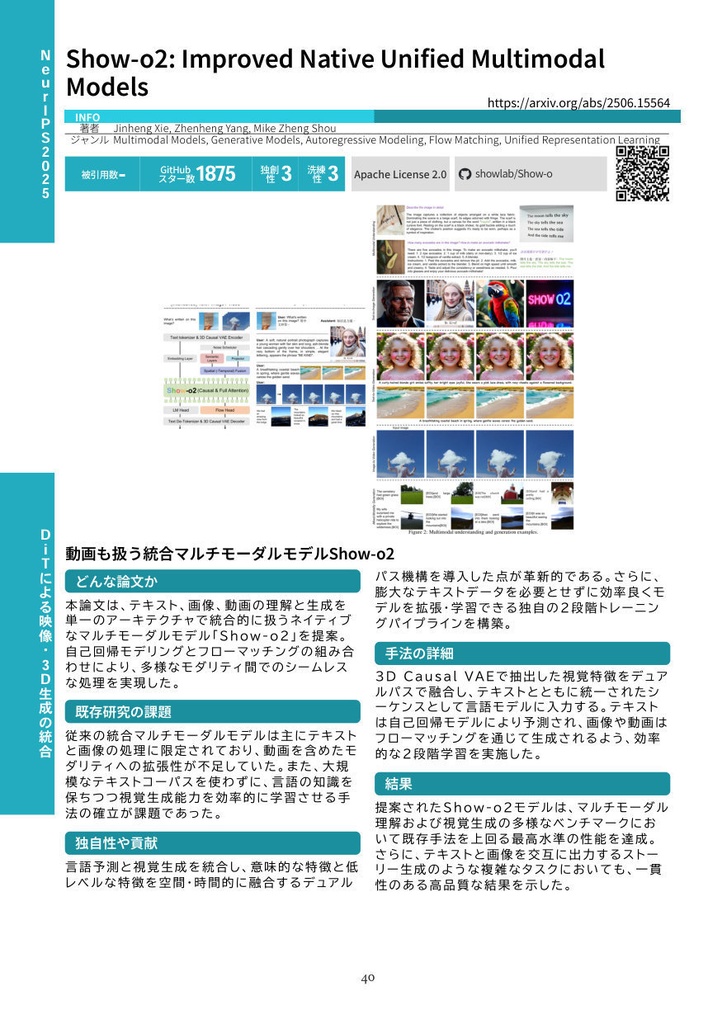
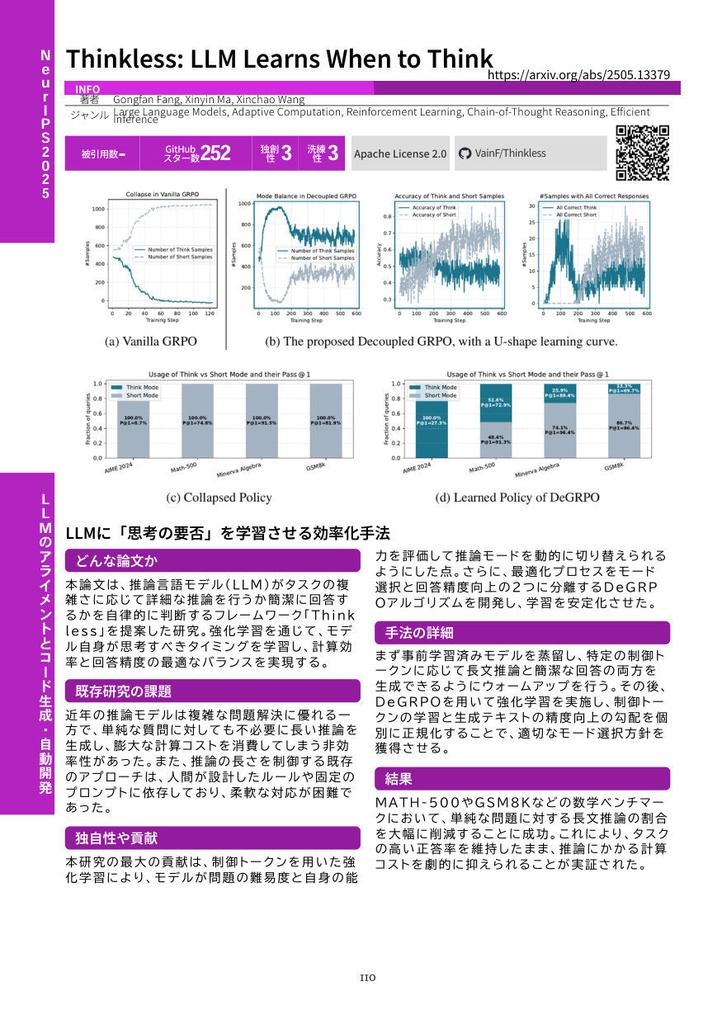
各論文について、以下の情報を掲載しています。 ・カンファレンス名・年度、論文タイトル、著者名、arXivリンク ・LLMによるジャンルタグ(5個) ・被引用数、GitHubスター数 ・LLMによるOriginality(独創性)・Elegance(洗練性)スコア ・GitHubライセンス情報、GitHubリポジトリへのQRコード ・LLMによる要約(どんな論文か?/既存研究の課題/独自性や貢献/手法の詳細/結果) ・論文中の最重要画像
過去のバージョンの紙の本
季節モノのため、過去の紙の本は在庫切れです。Amazonでは受注販売していますのでこちらをご利用ください ・2025年版 https://www.amazon.co.jp/dp/B0F8VN3MBK
対象読者
・最新のAI研究動向を効率よくキャッチアップしたい研究者・エンジニア ・商用利用可能なオープンソースAI技術を探している実務家・プロダクト開発者 ・限られた時間の中で「何を読むべきか」の指針が欲しい方 ・CV、NLP、音声、ロボティクスなど幅広い分野に関心のある方
各章の紹介
本書は全10章構成で、各章がAI研究の主要トピックを網羅しています。 【第1章】DiTによる映像・3D生成の統合 Diffusion Transformer(DiT)の学習効率化、3D Gaussian Splattingのスケーリング、動画生成におけるモーション制御、そして理解と生成を統合するマルチモーダル基盤モデルの最前線を扱います。Depth Anything 3、REPA-E、Structured 3D Latents、VACEなど40本を収録。 【第2章】視覚基盤モデルの進化とロボット操作学習 視覚言語モデルの推論強化、ロボティクス・具象化AIへの応用、SAM 3やYOLOv12などの視覚基盤モデルの進化、そして生成AIのセキュリティまでを網羅。強化学習を推論プロセスやロボット制御に導入する最新アプローチを22本収録。 【第3章】人物画像生成・3Dシーン理解・動画行動理解 拡散モデルによる高精度な人物生成とアイデンティティ保持、単眼画像からの3D空間推定、動画行動理解、リモートセンシング基盤モデルまで、物理世界と視覚情報を紐づける多彩なアプローチを11本収録。 【第4章】LLMのアライメントとコード生成・自動開発 LLMの自己対局による推論強化、SWE-GymやKimi-Devなどの自律的ソフトウェア開発エージェント、テキスト向け拡散モデル、三値化LLMによるエッジ推論、視覚言語融合検索など多岐にわたるテーマを26本収録。 【第5章】報酬モデルの高度化と特化型AIエージェント プロセス報酬モデル(PRM)のスケーリング、GUI操作・医療・Web探索などのドメイン特化エージェント、長文脈理解とRAGの高度化、SWE-benchシリーズの最新展開を18本収録。 【第6章】LLMアーキテクチャ革新と自然科学応用 TokenFormerやMulti-Token Predictionなどのアーキテクチャ革新、分子設計・タンパク質構造予測への生成モデルの応用、AI生成テキストの検出とセキュリティを16本収録。 【第7章】数理推論・定理証明と知識駆動エージェント DeepSeek-Prover-V1.5やContinuous Thought Machinesなどの高度な推論手法、WebWeaverによる動的RAG、Agent-as-a-Judgeによるエージェント評価、科学的発見ベンチマークを18本収録。 【第8章】音声・音楽生成と大規模音響モデル Stable Audio Open、JavisDiT++による音声・動画同時生成、低ビットレート音声コーデック、ゼロショット音声変換、音楽生成基盤モデルなど、音響AI分野の最前線を24本収録。 【第9章】生体信号AIと音声駆動アニメーション 脳波(EEG/MEG)と言語モデルを統合する生体基盤モデル、音声駆動の複数人対話動画生成、実環境音声処理、AIフェイク音声検知など新興分野の研究を6本収録。 【第10章】構造化基盤モデルとWebエージェント 時系列・表形式データの基盤モデル、Webブラウジングやコンピュータ操作を自動化するエージェント、気象予測やグラフ生成などの科学ドメイン向けモデルを19本収録。
目次
・はじめに ・第1章 DiTによる映像・3D生成の統合 ・Depth Anything 3 / Wan-Move / REPA-E / Diffusion as Shader / Structured 3D Latents / VGGT / RF-DETR / Show-o2 / VACE ほか全40本 ・第2章 視覚基盤モデルの進化とロボット操作学習 ・SAM 3 / Absolute Zero / Cosmos Policy / DeepEyes / Data Scaling Laws in Imitation Learning / Flow-GRPO ほか全22本 ・第3章 人物画像生成・3Dシーン理解・動画行動理解 ・FaceXFormer / UniPortrait / SkySense V2 / AnyCam / EmbodiedSAM ほか全11本 ・第4章 LLMのアライメントとコード生成・自動開発 ・Large Language Diffusion Models / SWE-Gym / Kimi-Dev / Samba / Bitnet.cpp / Thinkless / YuE ほか全26本 ・第5章 報酬モデルの高度化と特化型AIエージェント ・ReSearch / RM-R1 / ReTool / xLAM / SWE-bench Goes Live! / Scaling Agents ほか全18本 ・第6章 LLMアーキテクチャ革新と自然科学応用 ・TokenFormer / Multi-Token Prediction Needs Registers / Graph Diffusion Transformers / Concept Bottleneck Language Models ほか全16本 ・第7章 数理推論・定理証明と知識駆動エージェント ・DeepSeek-Prover-V1.5 / Continuous Thought Machines / WebWeaver / Agent-as-a-Judge / SynLogic ほか全18本 ・第8章 音声・音楽生成と大規模音響モデル ・DrVoice / Stable Audio Open / JavisDiT++ / FocalCodec / NotaGen / EMOVA ほか全24本 ・第9章 生体信号AIと音声駆動アニメーション ・BrainOmni / NeuroLM / Let Them Talk / SONICS ほか全6本 ・第10章 構造化基盤モデルとWebエージェント ・Moirai-MoE / WebThinker / ScaleCUA / TabDPT / OneForecast / DeFoG ほか全19本 ・手法の紹介と、昨年からの改良 ・限界と今後の展望
仕様
A5 / フルカラー / 237P ※2026年版
免責事項
本書のライセンス情報はLLMによる自動判定を含むため、誤りがある場合があります。最終的な確認はご自身の責任で行ってください。また、「手法の紹介と、昨年からの改良」「限界と今後の展望」以外のコンテンツは生成AI(LLM)により自動生成しています。