
簡単に動画を生成する「MovieGenerator」
- ダウンロード商品¥ 100
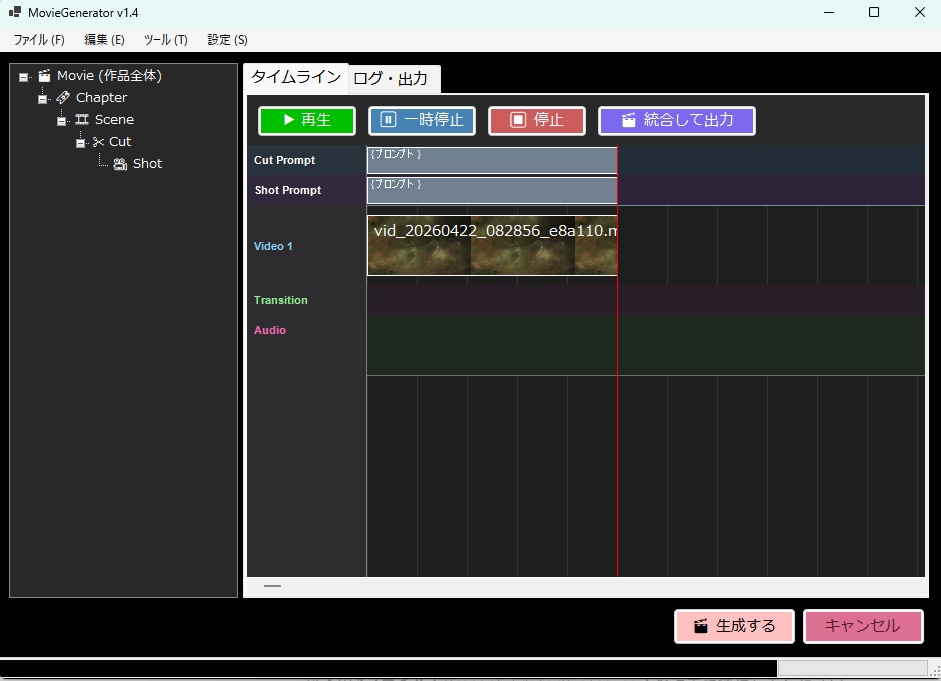
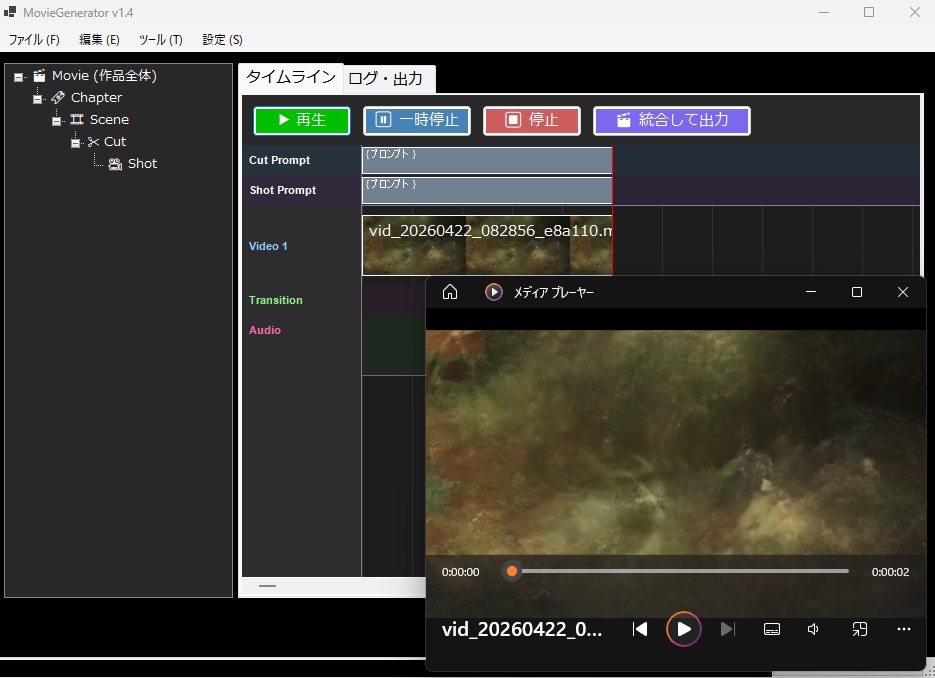
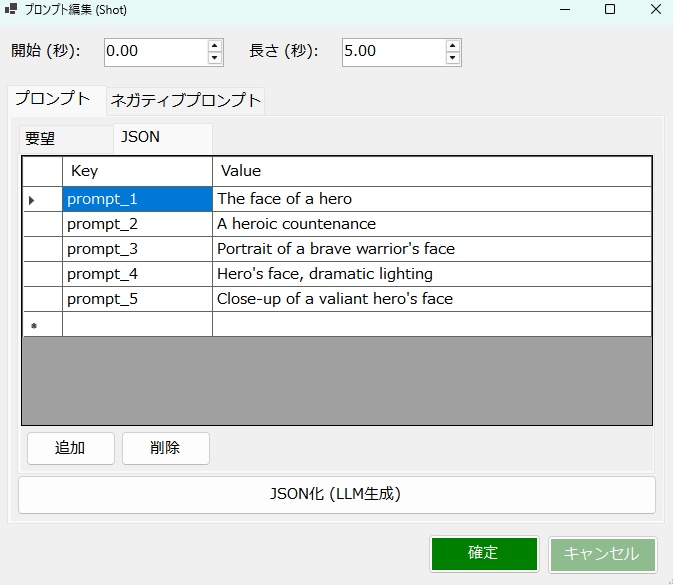
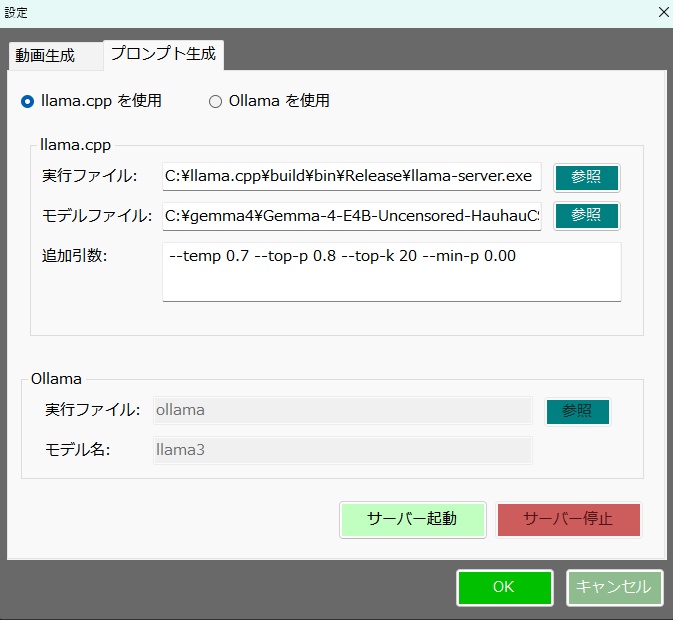
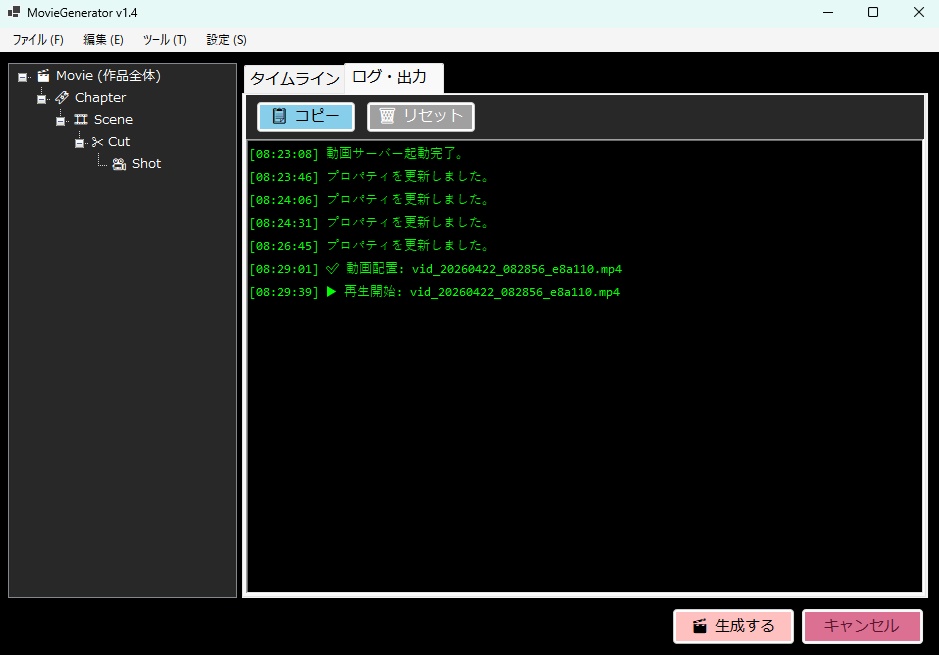
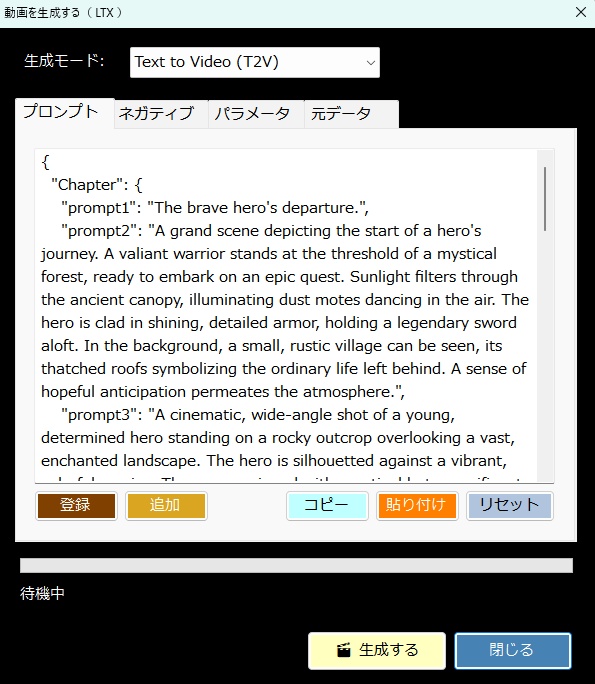
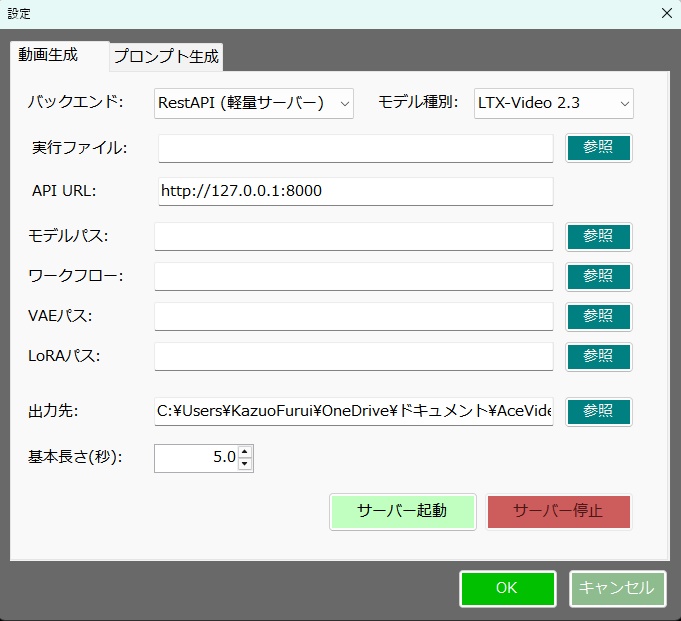
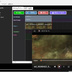
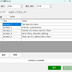
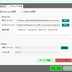
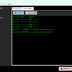
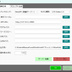
【概要】 ・LTX API (Rest API) を使って ローカルで動画を生成するツールです。 ・今のところは、 「ComfyUI」の使い方がわかりにくい という人向けの簡単なツールです。 ・基本的にはLTX用ですが、Wanのモデルも使えます。 ・クラウドAPIと違って課金なし。 ・プロンプト作成を補助するLLM (llama.cpp / Ollama)との連携機能も搭載。 《 セットアップの手順 》 ・setup.batをダブルクリックすると、 必要なライブラリなどのインストールが始まります。 ・モデルだとかを含めると、20GBぐらいになります。 ・不要になったらフォルダごと消すだけでOK。 ・ComfyUIをすでにインストールされている方は、 設定画面で、ComfyUIの実行ファイルへのパスを 指定するだけでも使えます。 ・プロンプト翻訳にLLM(llama.cppやOllama)を使用する場合は、 事前にそれぞれの実行ファイルやモデル(GGUF等)をご用意ください。 ⚠️ 事前準備:Hugging FaceアカウントとGemmaの利用承諾(必須) ・モデルの自動ダウンロードを行うにあたり、 テキストエンコーダである「Gemma-2-2b-it」は Googleの規約により利用承諾(ライセンス同意)が必須の ゲートモデルとなっています。 ・従って、このモデルファイルに関しては 手動でダウンロードする必要があります。 ・手順は以下のとおりです。↓(ver.1.7以降は必須) (1) Hugging Face で、アカウントを作成して下さい。(無料)↓ https://huggingface.co/ (2) Gemma-2-2b-it のページ にアクセスし、 規約に同意(Agree)する。↓ https://huggingface.co/google/gemma-2-2b-it (3) Hugging Faceの「Settings」→「Access Tokens」から、 トークン(Read権限)を発行してコピーしておく。↓ https://huggingface.co/settings/tokens ・ズラッと並んだ英語の項目のうち、 見るべきは 「Repositories」というセクションだけです。 ・「Read(読み取り)」に関する項目だけにチェックを入れてください。 ✅ Read access to contents of all public gated repos you can access (アクセスを許可されたパブリックモデルのデータを読み取る権限) 【チェックしてはいけない項目】 ・以下の単語が含まれているものは、 すべてチェックなし(空欄)のままで大丈夫です。 ❌ Write(書き込み・アップロードする権限) ❌ Manage または Delete(設定を変更したり削除したりする権限) ❌ Inference または Billing(有料の推論APIを使ったり、支払いに関する権限) (4) Hugging Faceへのログイン設定を行う 4-1. login_huggingface.bat をダブルクリックして実行してください。 4-2. 黒い画面が立ち上がり、トークンを入力: と表示されます。 4-3. 先ほどコピーした hf_ から始まるトークンを、 右クリックで貼り付けてください。 (※今度は貼り付けた文字が画面にしっかり表示されます) 4-4. トークンが正しく貼り付けられたことを確認し、 Enterキー を押します。 4-5. 「Login successful」と表示されれば完了です。 画面の指示に従ってウィンドウを閉じてください。 ※ これを行わないと、 setup.bat でのモデル自動ダウンロード時にエラーとなり、 動画生成ができません。 ※ すでに以前のバージョンをご利用中の方は、 最新の setup.bat を再度ダブルクリックするだけで、 自動的に新しい環境にアップデートされ、 不足しているモデルもダウンロードされます。 ■「Movie Generator」は、 最新のAIモデル(LTX-2.3 / Wan 2.2)を統合し、 テキストや画像から高品質な動画を生成するだけでなく、 「音声駆動(Audio-Driven)」によるキャラクターのリップシンク (口パク)と自然な表情変化をローカル環境で実現しました。 高度なリップシンク(LTX Audio / IA2V): ・参照画像と音声ファイルを指定するだけで、 LTX-2.3のTwo-Stageパイプラインが音声の波形を読み取り、 息継ぎや口の形まで音声に完全に同期した動画を生成します。 ゼロからの生命吹込み(Omnivoice連携): ・音声ファイルが手元になくても問題ありません。「音声プロンプト」を入力すれば、 内部でOmnivoiceがテキストを音声(TTS)に変換し、 そのままシームレスに動画のリップシンク駆動へと繋げます。 シームレスな長尺対応: ・メモリの限界を超える長尺動画も自動でセグメント分割。・映像チャンクの生成と音声セグメントの切り出しを並行して行い、 最終的にFFmpegで劣化なく完璧に結合(mux)します。 プロキシ(高速プレビュー)出力: ・本番出力前に、 超高速(ultrafast)&低解像度で タイムライン全体をレンダリングし、 トランジションや音声のタイミングを素早く確認できる プレビュー機能を搭載。 シンプルでユーザーフレンドリーなUI: ・生成して終わりではなく、 ドラッグ&ドロップ対応の 本格的なタイムラインと「ツリービュー」を搭載しています。 ・Movie(作品全体)>Scene>Shot の階層構造で プロンプトを管理。 ・タイムライン上での動画結合、 トランジション(効果)の自動調整、 クリップの途中からの「続きの生成(I2V)」など、 高度な編集機能により、 アイデア出しから 最終的な一本の動画の書き出しまで、 本ソフトのみで完結するワークフローを提供します。 ・作品全体のプロンプトを、 まとめて自動生成する機能を備えています。 ・お気に入りのプロンプトや生成動画を 階層化して保存できるライブラリ機能や、 llama.cpp / Ollama連携による 「自然言語からのJSONプロンプト自動翻訳」、 就寝中に大量の動画を自動生成できるツリー一括バッチ機能など、 生産性を最大化するための機能が 網羅されています。 📘 ユーザーマニュアル ■動画生成サーバー ・動画の生成には、LTX APIのサーバーを起動して行う方式と、 ComfyUI APIのサーバーを起動して行う方式とがあります。 ・ComfuUIをすでにダウンロードされている場合は、 それを利用するのがベストかと思います。 ・いずれにしても、モデルファイルなどを含めて、 10~20GB程度のディスク容量が必要になります。 ・動画生成に関しては、サーバーの実行ファイルのパスを 設定画面で設定する必要はありません。 ■テキスト生成サーバー ・プロンプトの生成や、翻訳で使用します。・llama.cppのサーバーを起動して行う方式と、 Ollamaのサーバーを起動して行う方式とがあります。 ・設定画面で、サーバーの実行ファイルのパスと、 使用するモデルファイルのパスを入力しておく必要があります。 (ollamaの場合は、ollama側でダウンロードしたモデル名を入力。) ■LTX と WAN の違い 【得意分野】 LTX-2.3 …実写・アニメ問わず安定した動き。IA2Vに極めて強い。 Wan 2.2 …複雑なモーション、非常に高い表現力。【音声に合わせた動画生成】 LTX-2.3 … ◎ (ネイティブ対応) ・公式の A2VidPipeline により、 単一ノード/APIで画像と音声を同時処理。 ・リップシンク精度が高い。 Wan 2.2 … △ (ワークフロー依存) ・Wan自体は音声を直接読まないため、 ComfyUIで InfiniteTalk 等の外部ノードを 組み合わせる必要がある。 【動画に合わせた音声生成】 LTX-2.3 … ◎ (Omnivoice連動) ・テキストから音声を生成し、 それを動画のシードにする。 Wan 2.2 … 〇 (Omnivoice連動) ・音声生成自体は可能。 【動作の重さ】 LTX-2.3 … 比較的軽量。 Wan 2.2 … 非常に重い(14Bクラス)。 3. 巨大なモデルを使用可能にする拡張設定 ★VRAM節約 (Offload Model / enable_model_cpu_offload()) 意味: ・AIモデル全体をVRAMに載せっぱなしにせず、 推論の「今使っているパーツ」だけをGPUに送り、 使い終わったらシステムRAMに戻す機能です。 ★データ型の最適化 (Convert Dtype / fp8変換) 意味: ・通常の16ビット浮動小数点(fp16 / bfloat16)のモデルウェイトを、 さらに小さい8ビット(fp8)に変換して計算します。 効果: ・画質の劣化を最小限に抑えつつ、VRAM消費を半減させます。・Wanのような巨大モデルでは必須です。 ★テキストエンコーダをCPU化 (T5 CPU) 意味: ・プロンプトを理解する「T5」という部品 (これだけでも数GBのVRAMを食う)の計算を、 GPUではなくCPUで行います。 効果: ・VRAMを大きく確保し、 その分を動画生成(U-Net / DiT)に回せます。・生成開始まで少し待たされます。 ★音声同期を有効にする (IA2V / TTS生成) 意味: ・これにチェックを入れると、 LTX APIに対して audio_path が送信され、 モデルが「画像」だけでなく 「音声の波形」も読み込んで 動画の動き(口の動きなど)を決定するようになります。 ■ベストな画質と速度を出すためのコツ ・RTX 3060(12GB)のポテンシャルを最大限に引き出す推奨設定です。 ★LTX-2.3 でのリップシンク動画生成 (最適解) バックエンド: RestAPI。 (軽量かつ高速です) 解像度: 848x480 (16:9) (12GB VRAMで最も安定し、品質が担保される解像度です。 HD以上はComfyUIでのfp8運用が必須になります) ステップ数 (Steps): 20 (LTXのTwo-Stageパイプラインは非常に優秀で、 15〜20で十分な高品質が得られます。 これ以上上げても速度が落ちるだけで変化は薄い。)CFGスケール: 3.0 〜 3.5 (これより高いと動画が破綻したり、色が焼ける。)VRAM節約フラグ: 全て「オン」推奨。(特にOffload Model)音声のコツ: 入力する音声は、BGMや環境音のないクリアな声 (ボーカルのみ)を使用してください。 ノイズが混ざると、モデルがそれを「口の動き」と誤認して 唇が震える原因になります。 ★Wan 2.2 を使う場合 バックエンド: ComfyUI (API) 必須。 ・Wanモデルは非常に重いため、 RestAPIでの直動は推奨しません。 ・ComfyUI側でfp8変換ワークフロー (workflowsフォルダ内のJSON)をしっかり組んで 呼び出すのがベストです。