
AI画像に証明を付ける「AiWaterMarker」
- Digital100 JPY
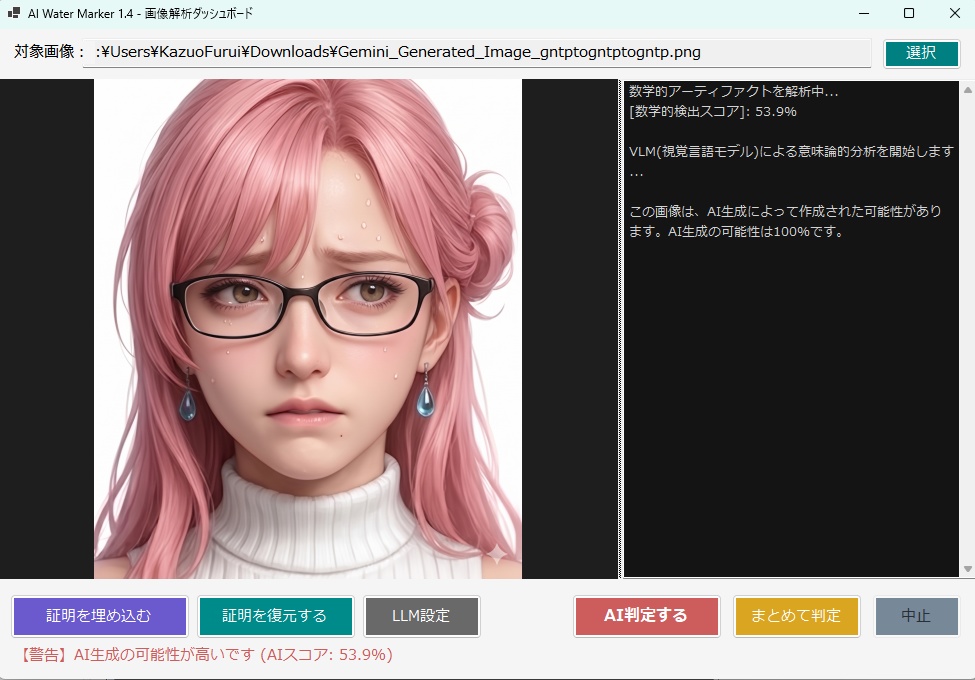
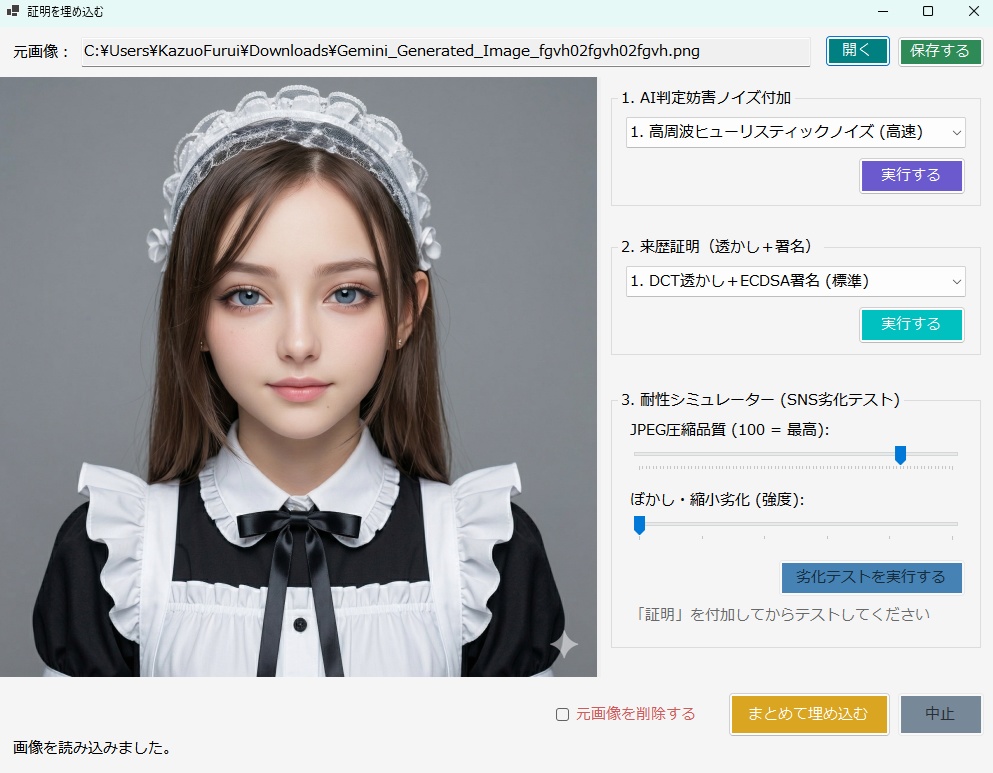
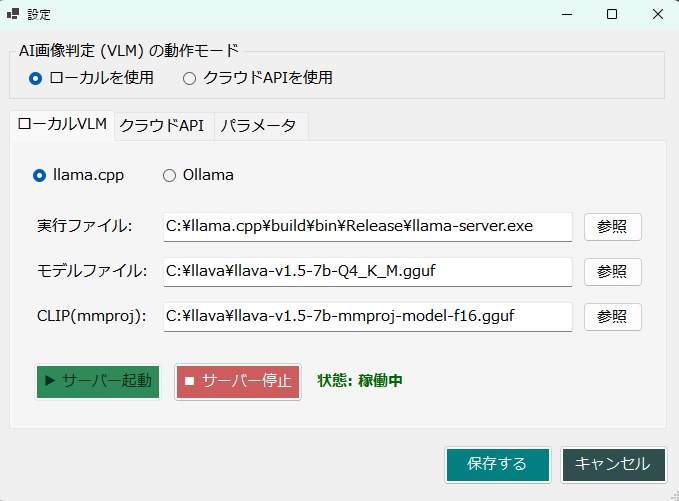
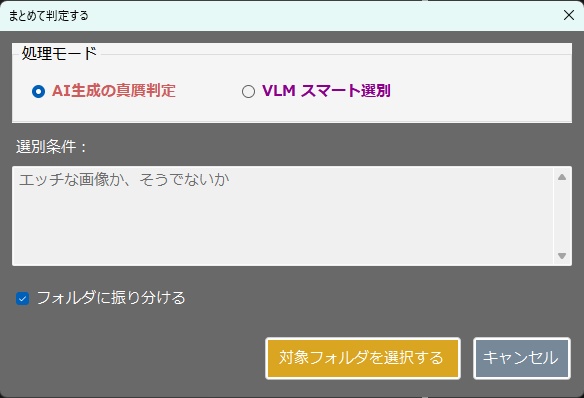
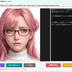
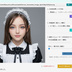
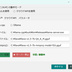
・AIによる意味理解判定を行う場合は、 以下のセットアップが必要です。↓ 【 llama.cppを使用する場合 】 モデルファイルは、こちらからダウンロードできます。↓ https://huggingface.co/second-state/Llava-v1.5-7B-GGUF/tree/main CLIP(mmproj)ファイルは、こちらからダウンロードできます。↓ https://huggingface.co/l3utterfly/llava1.5-7b-gguf/tree/main ※設定画面を開いて、このファイルのパスを指定しておいて下さい。 【 Ollamaを使用する場合 】 ・モデル名に llava を指定して保存してください。 《 各機能の説明 》 ・本ツールは「自分の作品を守る」機能(サブ画面)と、 「他人の画像を検証する」機能(メイン画面)の 2つの顔を持っています。 【防衛・証明機能】(サブ画面) ① AI判定妨害(アドバーサリアル攻撃) ・画像全体に 人間の目には見えない微小な数学的ノイズ (高周波ヒューリスティック、 またはVAE潜在空間攻撃)を付加します。 ・これにより、 第三者が「この画像はAI生成か?」と 判定ツールにかけた際、 AIの判定アルゴリズムを狂わせます。 ② 来歴証明(DCT透かし + ZKコミットメント) ・ブロックチェーンを使わず、 秘密の文字列(ソルト)と画像のハッシュを掛け合わせた 「ゼロ知識証明型」の署名を生成します。 ・これをEXIFメタデータだけでなく、 画像のピクセル(DCT周波数領域)に直接、 タイリング(多数決)方式で強力に埋め込みます。 ③ 耐性シミュレーター ・SNS(Xなど)にアップロードした際のJPEG圧縮劣化や、 縮小・ぼかし処理をメモリ上で疑似的に再現し、 付加した「証明」が実運用で生き残るかを 事前にテストします。 ④ セキュアワイプ(完全消去) ・透かしを入れた後、 ディスク上に残る「元の無防備な画像」を OSの標準削除ではなく、 ディスクセクタレベルでゼロ埋めして完全破壊し、 フォレンジック(データ復元)攻撃を防ぎます。 【検証・判定機能】(メイン画面) ⑤ ハイブリッドAI判定 ・対象画像に対し、 「数学的なノイズ(AI特有の格子アーティファクト)」をスキャンし、 同時にVLM(視覚言語モデル)で 「指の数やパースの狂いなどの意味論的矛盾」を解析させ、 総合的に真贋を判定します。 ⑥ ピクセル空間からの証明復元 ・メタデータが剥がされた画像であっても、 DCT空間から多数決方式でビットデータを抽出し、 隠された来歴証明を復元します。 ■RTX 3060 (12GB) 向けの具体的な推奨モデル ・VRAM 12GBという環境は ローカルAIにおいて非常に優秀ですが、 Windowsのシステム(約1.5GB〜2GB)と コンテキストウィンドウ(約1GB)の消費を考慮すると、 モデル本体に割けるVRAMの安全圏は 「7GB〜8GB前後」となります。 ・llama.cppをバックエンド(CUDA)で動かす場合、 安定性と解析精度のバランスが最も良い 「LLaVA v1.5 (7B)」の量子化モデルを推奨します。 ① モデルファイル(LlamaModelPath)の推奨 具体的なファイル名: llava-v1.5-7b-Q4_K_M.gguf 容量: 約 4.3 GB 理由: ・70億パラメータのモデルを4ビット量子化(Q4_K_M)したものです。 ・VRAM消費が少なく、 RTX 3060のCUDAコアであれば 驚異的な速度(数十トークン/秒)で回答を生成できます。 ・画像の矛盾を指摘する推論能力としては 十分な賢さを持っています。 ② CLIPプロジェクターファイル(LlamaMmprojPath)の推奨 具体的なファイル名: llava-v1.5-7b-mmproj-f16.gguf 容量: 約 620 MB 理由: ・VLMが画像を解釈するための「目」となるファイルです。 ・mmprojは、極端に量子化すると 画像の細部(ノイズや指の崩れなど)を見落としやすくなるため、 16ビット(f16)の標準サイズを使うのがベストプラクティスです。