
シンプルな翻訳AI「TransAI」
- Digital100 JPY
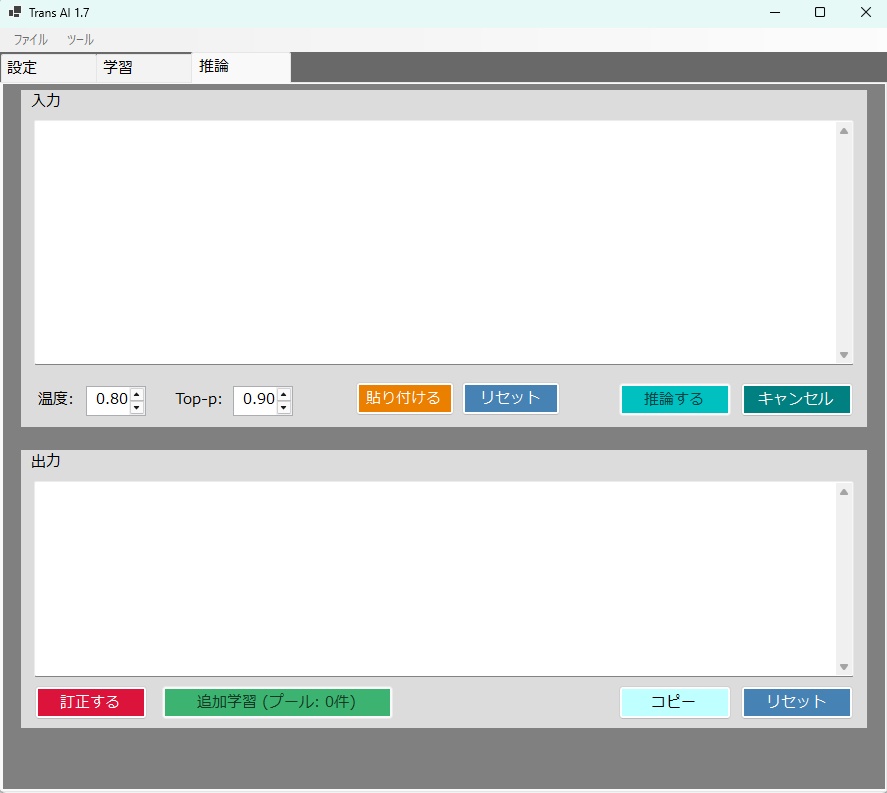
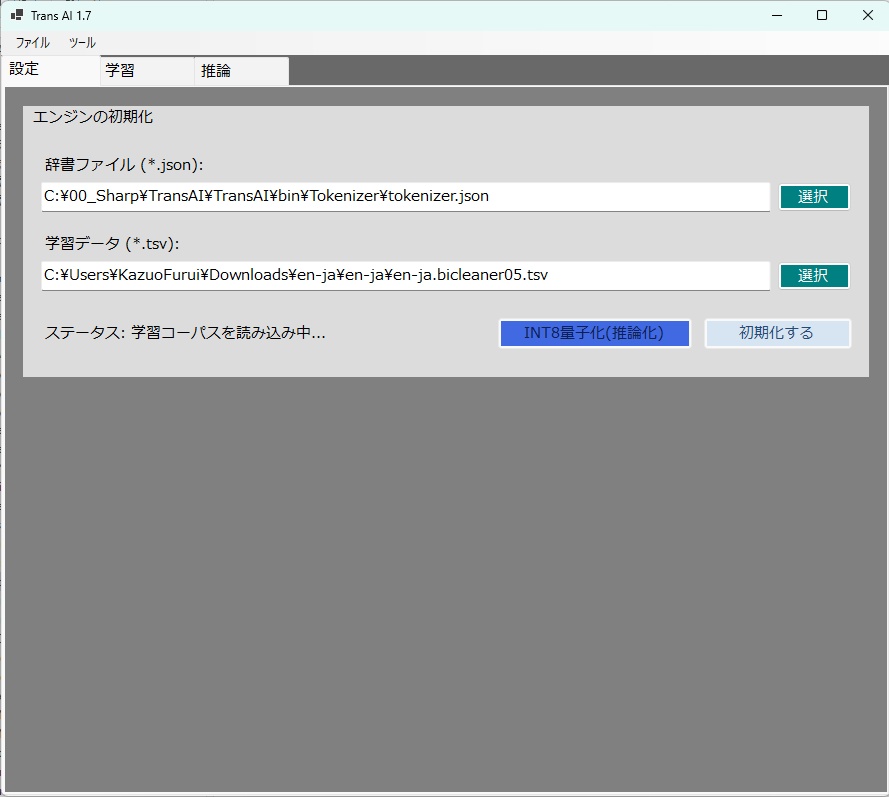
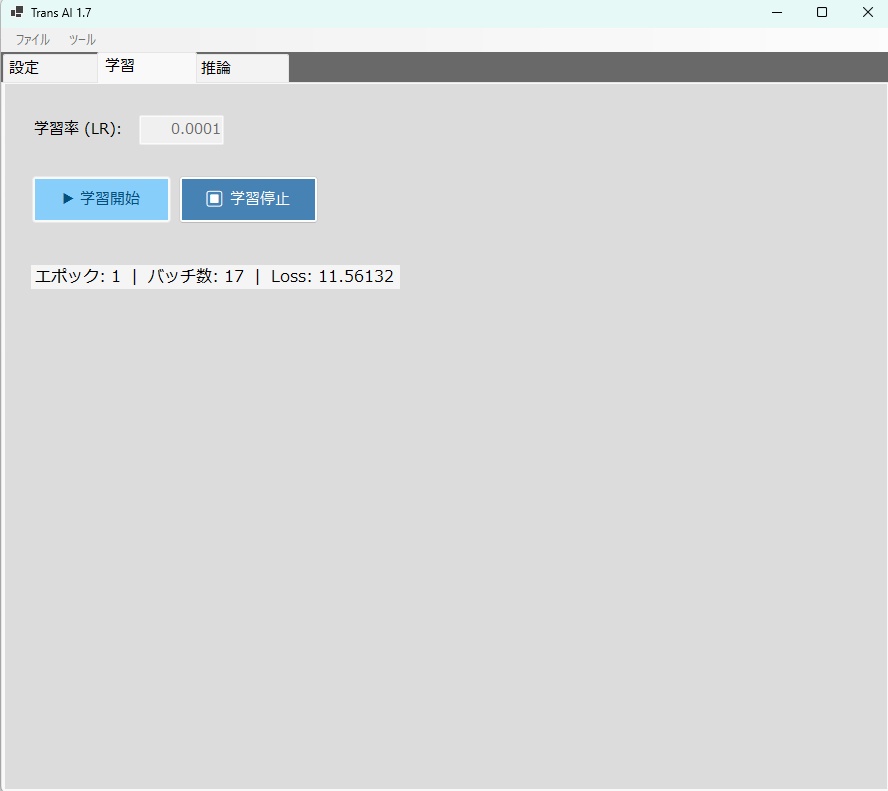
・いろいろと技術的なテストをするために作った簡単なもので、 これが一番すごい!・・・とかいうものではないんですが、 一応、使えるのではないかなと思います。 《 ボキャブラリファイル(tokenizer.json)の入手先 》 ・翻訳モデルは「ゼロから学習(スクラッチ)」させますが、 文字をIDに変換するルール(ボキャブラリ)だけは、 世界トップクラスの多言語モデルから拝借することで、 学習効率が劇的に向上します。 ・おすすめは、 現在最も日本語と英語の分割(トークナイズ)が優秀な Qwen または Llama のボキャブラリです。 ・どちらもHugging Faceから無料でダウンロードでき、 知財的にも安全(Apache 2.0 / Llamaライセンス)です。 おすすめ: ・Qwen の tokenizer.json (語彙数 約15万) ・特に日本語・中国語・英語の多言語処理に優れています。 ダウンロードURL (Hugging Face): https://huggingface.co/Qwen/Qwen2.5-7B/tree/main 手順: 上記リンクにアクセスします。 ・画面の右側にある 「↓(Download file)」 ボタンをクリックします。 ・ダウンロードした tokenizer.json を、 TransAI.exe と同じフォルダ(または任意の場所)に配置します。 (※Llamaのボキャブラリを使いたい場合は、 Hugging Faceのアカウントを作成し、 Meta社への利用申請ボタンを押す必要があります。 Qwenは申請不要で、すぐにダウンロードできます。) ■対訳コーパス(学習データ)の準備 ・もし手元に「英語と日本語の対訳テキスト」がない場合は、 テスト用として以下のデータセットを利用できます。 JParaCrawl v3.0 (商用・研究利用可能な大規模日英コーパス) ・日本のNTTなどが構築した、 Web上の翻訳文を収集した 巨大なデータセットです。 ダウンロードURL: https://www.kecl.ntt.co.jp/icl/lirg/jparacrawl/ 手順: ・上記サイトから データセット(tar.gz または zip)を ダウンロードして解凍します。 ・英語と日本語の文章が 「タブ(\t)区切り」で並んでいるテキストファイルを探します。 (例:en-ja.bicleaner05.txt) ・このファイルを corpus.tsv などの名前で保存し、読み込ませます。 (※数千万行あるため、 最初は先頭の1万行だけを切り出した 小さなファイルで学習テストを行うことを強くお勧めします。) ■ハイパーパラメータの意味(AIの「脳の構造」) ・これらは「設定」タブで決める、 AIのアーキテクチャ(構造)そのものです。 ・一度決めて初期化・学習を始めたら、 途中で変更することはできません。 (変更して読み込もうとすると、 アーキテクチャ不一致エラーになります) バッチサイズ (Batch Size): ・GPUが「同時に処理する文章の数」です。 ・16に設定すると、 16個の翻訳文をまとめて並列計算します。 ・大きくするほど学習スピード(効率)は上がりますが、 ビデオメモリを爆発的に消費します。 最大系列長 (Max Sequence Length): ・AIが一度に読み込める 「文章の長さ(トークン数の上限)」です。 ・128に設定すると、 128単語以上の長い文章はスパッと切り捨てられ、 短い文章は128になるまで 「PAD(空白)」で埋められます。 ・これもビデオメモリの消費に直結します。 隠れ層サイズ (Hidden Size): ・AIの「脳の太さ(表現力)」です。 ・512という次元数で 言葉の意味をベクトル化します。 ・この数字を大きくする(例: 1024, 2048)と、 より複雑なニュアンスを理解できる 賢いモデルになりますが、 計算量が指数関数的に増えます。 レイヤー数 (Layers): ・Transformerの思考回路(Attentionブロック)を 「何段重ねるか」です。 ・6に設定すると、 AIは入力された言葉を 6回熟考して出力を作ります。 ・深い(多い)ほど 文脈の理解力が高まります。 ■学習ステータスの意味(AIの「成長度合い」) ・学習タブに表示されているリアルタイムな数値です。 エポック (Epoch): ・用意した学習データ(数十万行のテキストなど)全体を 「何周したか」です。 ・エポック 1 は、1周目の学習中であることを示します。 バッチ数: ・これまでに重み(知識)の更新を行った回数です。 ・画像では「12,780回」更新されたことがわかります。 Loss (損失): ・AI開発において最も重要な数字です。 ・AIが出した翻訳と、 正解の翻訳が 「どれくらいズレているか(間違いの大きさ)」 を表します。 ・学習が進むにつれて 8.5 → 5.2 → 2.1... と、 限りなく 0 に近づいていくのが正常な状態です。 ■継続学習(中断と再開)は可能なのか? ・はい、完全に可能です。 ・AIの「知識(重み行列)」だけでなく、 現在の学習の進み具合(adamStep)も 一緒に .trai ファイルに保存されます。 ・途中で「学習停止」を押して「上書き保存」し、 アプリを閉じても大丈夫です。 ・次回起動時に、そのファイルを「開く」で読み込み、 「学習開始」を押せば、 前回の知識を引き継いだまま 途中から学習を再開できます。 🚨 【超重要】「Loss: NaN」について ・これはAIの学習が「崩壊」している状態です。 ・NaNは「Not a Number(非数)」の略です。 ・GPUの中で行列の掛け算をしている最中に、 数値が無限大(Infinity)を超えてオーバーフローしたか、 ゼロ除算が発生したことを意味します。 ・この状態になると AIの脳内は「真っ白」になっており、 このまま何時間学習させても、保存しても、 一切使い物になりません。 (推論させても無言になるか、エラーを吐きます) ■初期化は毎回必要なのか?(HDDのフォーマットと同じ?) 👉 はい、おっしゃる通り「フォーマット (ビデオメモリの確保と、脳の初期化)」です。 ・そのため、アプリ運用時のルールは以下のようになります。 新規作成時: ・「初期化する」を押す(VRAMを確保し、脳をランダムな値で初期化)。 前回からの続きを学習時: ・「初期化する」を押した直後に、 「読み込む」を押す。 (ランダムになった脳に、 前回保存した知識を上書きする。) ※もし学習の途中で間違えて 「初期化する」を押してしまうと、 知識がすべて消し飛んで ゼロに戻ってしまうのでご注意ください。 🚀 総合アーキテクチャ分析レポート ・本システム「TransAI」は、 Python等の巨大なエコシステムに依存せず、 C#とネイティブCUDA C++のみでゼロから構築された、 極めて独自性の高いローカルLLMエンジンです。 ・RTX 3060等の12GB VRAMという厳しいハードウェア制約の中で、 巨大なモデルを動かすために、 ソフトウェアアーキテクチャの極限を追求しています。 1. よく知られた標準機能 ・TransAIは、現代のLLM開発において必須とされる 高度な最適化技術をネイティブレベルで完全実装しています。 FP16 Mixed Precision (混合精度学習): 仕組み: 重みの保存やオプティマイザ(AdamW)の計算は精度の高いFP32(32ビット)で行い、行列の掛け算などの重い処理の瞬間だけFP16(16ビット)に変換してGPUの「Tensor Core」に処理させます。 効果: 計算速度が飛躍的に向上し、学習時のVRAM消費を大幅に抑えます。 KV Cache (キー・バリュー キャッシュ): 仕組み: 自己回帰推論(文章を1単語ずつ生成する処理)において、過去に計算した単語のAttention情報(KeyとValue)を専用のVRAM領域に保存しておき、次の単語を生成する際は「最新の1単語」だけを計算して過去のキャッシュと照合します。 効果: 計算量が $O(N^2)$ から $O(1)$ へと激減し、長文になっても生成速度が落ちません。 FlashAttention (Fused Memory-Efficient Attention): 仕組み: 通常、Attentionの計算過程で作成される巨大なスコア行列はVRAMを食いつぶします。これを、GPUチップ内の超高速なSRAM(共有メモリ)の中で分割計算(Tiling)し、結果だけをVRAMに書き出します。 効果: 長い文脈(MaxSeqLength)を設定してもVRAMが爆発(OOM)しなくなり、メモリアクセスの待ち時間が消滅して高速化します。 W8A16 INT8 Dynamic Quantization (動的量子化): 仕組み: 学習が完了したFP32の重みを、1/4のサイズであるINT8(8ビット整数)に圧縮してVRAMに保持します。推論の計算の瞬間だけ、GPUカーネル内でFP16に展開(Dequantize)して計算に掛けます。 効果: VRAM消費量が劇的に減少し、12GBの環境でもより巨大なモデルをロードできるようになります(推論専用)。 Temperature / Top-P Sampling: 仕組み: 常に最も確率の高い単語を選ぶのではなく、確率分布に「温度」を掛けて平準化し、上位数%(Top-P)の候補の中からルーレットで次の単語を選びます。 効果: AIの出力が機械的な直訳から、人間らしい自然な「ゆらぎ」や「創造性」を持った文章に変化します。 2. TransAI の独自機能の仕組み ・本システムの特徴は、 限られたVRAMを無限のように見せかける 独自のストリーミング技術です。 Predictive Streaming(疑似量子アニーリング連携): 仕組み: C#側でユーザーの入力テキストを監視し、ETW(Windowsイベントトレース)を経由してバックグラウンドで「次にAIがどの専門知識(法律、ITなど)の重みを必要とするか」を予測します。 QUBO最適化: 予測されたドメイン情報を基に、疑似量子アニーリング(SBA)アルゴリズムが「どの圧縮形式(RawかQuantizedか)でVRAMへロードするのが最も時間とメモリのコスパが良いか」を瞬時に計算します。 非同期VRAM転送: 最適な重みデータを、AIがメインで計算を行っている裏側(cudaStream_t)でこっそりとVRAMへ流し込みます。 効果: ユーザーが推論ボタンを押す頃には、すでに必要な専門知識がVRAM上にセットされています。これにより、12GBの限界を超えた巨大な知識群を、一切のロード時間(フリーズ)なしでシームレスに使い分けることが可能になります。